제품문의
제품과 관련하여 궁금하신 사항을
문의하기를 통해 해결하세요.
AI and Data Science
Data Center &
Cloud Computing
Design and
Visualization
Robotics &
Edge Computing
HPC-Performance
Computing
Self-Driving Vehicles
NVIDIA Blackwell Architecture
CUDA Cores 24,064
AI TOPS 3511 AI TOPS
Single-Precision Performance 110 TFLOPS
RT Core Performance 333 TFLOPS
Tensor Performance 1457.0 TFLOPS
GPU Memory 96 GB GDDR7 with ECC
Memory Interface 512-bit
Memory Bandwidth 1792 GB/sec
System Interface PCI Express 5.0 x16
Display Connectors 4x DisplayPort 2.1b
Maximum Power Consumption 300W

고밀도 워크스테이션 구성(최대 GPU 4개)에 최적화된 이 Max-Q 변형은 성능과 전력 효율성 간의 균형을 맞춰 확장 가능한 워크플로우를 제공합니다. 대규모 데이터 모델링, 분산 렌더링, 멀티 인스턴스 AI 학습 및 추론과 같은 멀티 GPU 워크로드에 완벽합니다.
96GB의 초고속 GDDR7 메모리를 탑재한 NVIDIA RTX PRO 6000 Blackwell은 탁월한 성능과 유연성을 제공하여 에이전틱 AI, 물리 AI 및 과학 컴퓨팅에서 렌더링, 3D 그래픽 및 비디오에 이르기까지 광범위한 사용 사례를 가속화할 수 있도록 합니다.
RTX PRO 6000 Blackwell 서버 에디션은 강력한 RTX AI 및 그래픽 성능을 제공하며, 24/7 데이터 센터 환경에서 운영될 수 있도록 수동 냉각 방식으로 설계되었습니다. MIG를 지원하여 각 GPU는 최대 4개의 독립된 인스턴스로 분할될 수 있으며, 각 인스턴스는 24GB의 메모리를 할당받아 동시에 AI 및 그래픽 작업을 실행할 수 있습니다.
RTX PRO 6000은 NVIDIA Confidential Computing을 통해 안전한 AI를 구현한 최초의 범용 GPU로, 강력한 하드웨어 기반 보안을 통해 AI 모델과 민감한 데이터를 무단 액세스로부터 보호합니다. 이를 통해 데이터가 사용 중인 동안 전체 워크로드를 보호하기 위해 물리적으로 격리된 신뢰할 수 있는 실행 환경을 제공합니다.
딥 러닝 워크스테이션 솔루션을 통해 작업 공간에서 편리하게 AI 슈퍼 컴퓨팅 성능을 활용하고 NGC에서 필요한 모든 딥 러닝 소프트웨어를 사용할 수 있습니다. 이제 딥 러닝을 필요로 하는 누구든지 데스크 사이드 딥 러닝을 시작할 수 있습니다.
모든 엔터프라이즈에서 물리적 데이터센터를 구축할 필요 없이 손쉽게 대규모 컴퓨팅 성능에 액세스할 수 있습니다. AI, 고성능 컴퓨팅(HPC) 및 의료 영상 활용, 차세대 그래픽 기술 적용 등 워크로드 전반에서 최고 성능을 경험할 수 있습니다.
GPU 가속 데이터센터는 원하는 규모와 더 적은 수의 서버로 컴퓨팅 및 그래픽 워크로드에 혁신적인 성능을 제공하여 더 빠르게 정보를 얻고 비용을 획기적으로 절감할 수 있습니다. 가장 복잡한 딥 러닝 모델을 트레이닝하여 가장 심각한 문제를 해결하세요.
현대 기업은 이제 수 십억 개의 IoT 센서를 통해 생성 된 데이터를 활용해 더 빠른 통찰력과 시간과 비용 절감을 할 수 있습니다. 실시간으로 결정을 내리고 강력하고 분산 된 컴퓨팅과 안전하고 간단한 원격 관리 및 업계 최고 기술과의 호환성을 기대할 수 있습니다.
Blackwell은 최신 SM 및 CUDA® 코어 기술로 제작된 가장 강력한 전문가용 RTX GPU입니다. 이 SM은 향상된 처리 처리량과 프로그래밍 가능한 셰이더의 내부에 뉴럴 네트워크를 통합한 새로운 뉴럴 셰이더를 탑재해 향후 10년의 AI 증강 그래픽 혁신을 주도합니다.
새롭게 향상된 GDDR7 메모리는 대역폭과 용량을 크게 향상시켜 애플리케이션이 더 빠르게 실행되고 더 크고 복잡한 데이터세트를 처리할 수 있도록 지원합니다. 96GB의 GPU 메모리를 사용하여 대규모 3D 및 AI 프로젝트를 처리하고, 대규모 VR 환경을 탐색하며, 대규모 멀티 앱 워크플로우를 구현합니다.
4세대 RT 코어는 이전 세대 대비 최대 2배의 성능을 제공하며, M&E 콘텐츠 제작, AECO 설계, 제조 프로토타이핑을 위한 렌더링을 가속화합니다. RTX Mega Geometry와 같은 뉴럴 그래픽 기반 기술을 활용하여 사실적이고 물리적으로 정확한 장면과 몰입감 넘치는 3D 디자인을 생성하고, 최대 100배 더 많은 레이 트레이스드 트라이앵글 구현합니다.
5세대 Tensor 코어는 이전 세대 대비 최대 3배 향상된 성능을 제공하며, FP4 정밀도 및 DLSS 4 Multi Frame Generation 기술을 지원합니다. 로컬 LLM을 가속화하고, 새로운 AI 모델의 프로토타입을 만들며, 향상된 콘텐츠 제작 및 그래픽을 구현하세요.
멀티 인스턴스 GPU(MIG)는 최대 4개의 완전 격리된 인스턴스를 생성할 수 있도록 하여 RTX PRO 6000 서버 에디션의 성능과 가치를 확장합니다. 각 MIG 인스턴스는 고유의 고대역폭 메모리, 캐시, 컴퓨팅 코어를 탑재하며 보장된 서비스 품질(QoS)을 갖추고 있어 모든 사용자가 가속 컴퓨팅 리소스를 사용할 수 있도록 지원합니다.
전문가들은 이제 탁월한 시각적 선명도와 성능을 달성하여 최대 4K (120Hz), 16K(60Hz)의 고해상도 디스플레이를 구동할 수 있습니다. 대역폭을 늘리면 멀티 모니터를 원활하게 설정할 수 있어 멀티태스킹과 협업에 이상적입니다. 또한, HDR과 고해상도 색상 지원으로 비디오 편집, 3D 디자인, 라이브 방송과 같은 정밀한 작업에 탁월한 색상 정확도를 보장합니다.
9세대 NVIDIA NVENC 엔진은 비디오 인코딩 속도를 획기적으로 높이고, 전문 비디오 애플리케이션의 품질을 향상합니다. 4:2:2 H.264 및 HEVC 인코딩에 대한 새로운 지원을 추가하고 HEVC 및 AV1 인코딩 품질을 향상합니다.
6세대 NVIDIA NVDEC 엔진은 최대 2배의 H.264 디코딩 처리량을 제공하고 4:2:2 H.264 및 HEVC 디코딩을 지원합니다. 전문가들은 고품질 비디오 재생의 이점을 누리고, 비디오 데이터 수집을 가속화하며, 고급 AI 기반 비디오 편집 기능을 사용할 수 있습니다.
PCI Express 5세대 지원을 통해 PCIe 4세대보다 2배의 대역폭을 확보하여 CPU 메모리의 데이터 전송 속도를 높이고, AI, 데이터 사이언스, 3D 모델링과 같은 데이터 집약적인 작업에 더 빠른 성능을 발휘합니다.
AI 개발 및 추론 워크로드를 가속화하고 에이전틱 AI 애플리케이션을 구축하세요.

데이터 파이프라인을 가속화하세요.

향상된 정확도로 과학적 혁신을 가속화하세요.

놀랍도록 사실적인 디자인과 시뮬레이션을 빠르고 정밀하게 제공하세요.

라이브 미디어 및 비디오 파이프라인의 성능을 높이세요.

최신 세대 RTX 기능, 4개의 비디오 인코딩 및 4개의 비디오 디코딩 엔진을 사용하여 완전히 새로운 워크플로를 사용하고 새로운 크리에이티브 기능을 활용해 보세요.
RTX PRO 6000은 강력한 AI, 비주얼 컴퓨팅과 미디어 가속화 기능을 제공하여
라이브 미디어, 게임 개발, 영화 및 텔레비전 전반에 걸쳐 콘텐츠의 생성, 관리, 배포 및 소비 방식을 혁신합니다.
AI 기반 워크플로와 도구에는 반복적인 작업을 자동화하고 아티스트의 창의적 흐름을 유지하기 위해 대용량 메모리를 갖춘 강력한 GPU가 필요합니다.
가상 제작과 카메라 내부 시각 효과는 실시간 레이 트레이싱, 딥 러닝 슈퍼 샘플링(DLSS), 대규모 환경을 실시간으로 처리하기 위한 대용량 메모리 용량 등의 고급 기능을 사용합니다.
사전 시각화 또는 사전 제작 작업을 통해 자산, 샷, 창의적인 콘텐츠를 검토하고 디자인 과정에서 신속하게 창의적인 결정을 내려 시간과 비용을 절약하세요.
AR/VR을 활용한 콘텐츠 제작 및 위치 기반 엔터테인먼트를 통해 몰입형 경험과 청중 참여를 촉진하세요.

가장 큰 장면과 다중 애플리케이션 워크플로우를 위한 맞춤형 메모리를 제공하는 NVIDIA RTX™ 및 NVIDIA Quadro 전문 솔루션으로 가장 복잡한 렌더링 워크로드를 처리하세요. NVIDIA OptiX™ AI 가속화 노이즈 제거 기능으로 복잡한 렌더링 작업을 자동화 및 가속화하고 전문 시각화를 위한 NVIDIA EGX 플랫폼을 통해 데이터센터에 유연한 고성능 렌더링의 성능을 도입하세요.

NVIDIA Iray는 조명과 재료의 실제 동작을 시뮬레이션하여 전문가가 인터랙티브 및 배치 렌더링 워크플로우를 위한 사실적인 이미지를 생성할 수 있도록 해주는 최첨단 렌더링 기술입니다. RTX 하드웨어에 대한 지원은 실시간 레이 트레이싱 및 AI 가속화 노이즈 제거를 제공하여 디자이너와 디지털 아티스트가 시각적으로 놀라운 렌더링을 제작하기 위해 필요한 동시에 워크플로우를 상당히 가속화하는 도구를 제공합니다.

NVIDIA vMaterials는 디자인 및 AEC 워크플로에 사용되는 일반적인 실제 재료를 나타내는 MDL 재료 및 조명의 선별된 컬렉션입니다. Iray 또는 MDL SDK를 통합하면 셰이더를 작성하지 않고도 사용할 준비가 된 수백 가지 재료 라이브러리를 애플리케이션에 빠르게 가져올 수 있습니다. 재료는 일관된 스케일로 제작되므로 설계자는 스케일을 다시 조정할 필요 없이 재료에서 재료로 쉽게 전환할 수 있습니다.
그래픽 파이프라인 중 버텍스, 테셀레이션, 지오메트리 쉐이딩 단계에 새로운 쉐이더 모델을 제공하여 지오메트리 연산에 보다 유연하고 효율적으로 접근할 수 있습니다.
텍스처 공간 셰이딩을 사용하면 개체가 메모리에 저장된 개인 좌표공간(텍스처 공간)에서 음영 처리되고 픽셀 셰이더는 결과를 직접 평가하지 않고 해당 공간에서 샘플링합니다.
Variable Rate Shading (VRS)는 프레임의 다른 영역에 대한 음영 비율을 변경하여 렌더링 성능과 품질을 향상시킵니다. VRS 래퍼를 사용하면 개발자가 포비티드 렌더링을 위해 HMD의 시선 추적 기능을 더 쉽게 통합할 수 있으며 이미지 품질 및 성능을 위한 편리한 사전 설정과 맞춤형 구성 지원이 포함됩니다.
Multi-View Rendering (MVR)은 Pascal의 SPS (Single Pass Stereo)를 강력하게 확장합니다. SPS는 X 오프셋을 제외하고 공통된 두 뷰의 렌더링을 허용했지만 MVR에서는 뷰가 완전히 다른 원점 위치 또는 뷰 방향을 기반으로하는 경우에도 단일 패스로 여러 뷰를 렌더링 할 수 있습니다.

NVIDIA Blackwell GPU 아키텍처는 4:2:2 크로마샘플링된 비디오에 하드웨어 인코딩 및 디코딩 지원을 추가하여 이 형식으로 작업할 때 엄청난 성능 이점을 제공하여 전문가들이 프록시를 기다리고 저글링하는 데 더 적은 시간을 할애하고 다음 걸작을 제작하는 데 더 많은 시간을 할애할 수 있게 합니다. 4:2:0에 비해 4:2:2로 유지되는 추가 색상 정보는 HDR 콘텐츠와 텍스트 또는 미세한 선이나 워크플로우와 같은 세밀한 디테일을 유지하는 데 특히 유용하며, 색상 등급을 매길 때처럼 소스가 색상을 반복적으로 수정할 수 있습니다.
최신 세대 RTX 기능, 4개의 비디오 인코딩 및 4개의 비디오 디코딩 엔진을 사용하여
완전히 새로운 워크플로를 사용하고 새로운 크리에이티브 기능을 활용해 보세요.
RTX PRO 6000은 강력한 AI, 비주얼 컴퓨팅과 미디어 가속화 기능을 제공하여 라이브 미디어,
게임 개발, 영화 및 텔레비전 전반에 걸쳐 콘텐츠의 생성, 관리, 배포 및 소비 방식을 혁신합니다.
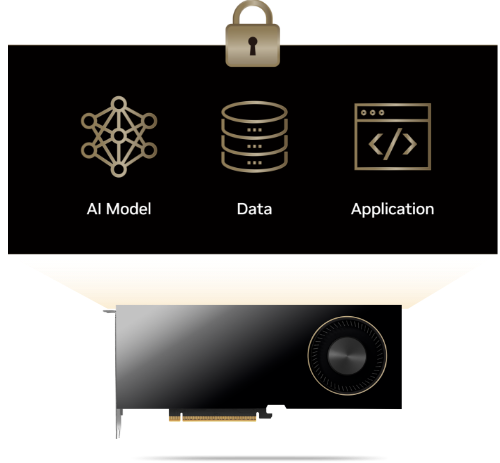
RTX PRO 6000 GPU는 물리적으로 분리된 신뢰 실행 환경(TEE)과 내장형 방화벽을 통해 전체 워크로드를 완전히 격리된 가상 머신에서 안전하게 실행할 수 있도록 보장합니다.
하이퍼바이저, 호스트 운영체제, 물리적 접근자 등 무단 주체는 실행 중인 데이터, AI 모델, 애플리케이션에 접근하거나 이를 수정할 수 없습니다.
RTX PRO 6000 GPU는 인증된 사용자만 데이터와 코드를 실행할 수 있으며, 장치 인증을 통해 펌웨어 변조 없이 정품 GPU와 안전하게 통신하고 있다는 확신을 제공합니다.
NVIDIA의 GPU 최적화 소프트웨어를 사용하여 보안, 프라이버시, 규제 요건을 충족하면서도 RTX PRO 6000 GPU에서 AI 워크로드 전체를 가속화할 수 있습니다. 코드 수정 없이 그대로 사용 가능합니다.

각 프레임 잠금 커넥터는 프레임 잠금 케이블과의 연결을 고정하여 견고한 연결성과 최대 생산성을 제공하기 위해 자체 잠금 유지 메커니즘으로 설계되었습니다.
3D 스테레오 하드웨어를 NVIDIA RTX PRO 그래픽 카드에 직접 동기화하는 전용 연결을 통해 스테레오 효과를 강력하게 제어합니다.
특히 현재의 대형 와이드스크린 디스플레이 시대에는 단일 대형 디스플레이 또는 다중 디스플레이 환경에서 생산성 향상을 위해 데스크톱 환경을 최종 사용자가 전례 없이 제어할 수 있습니다.
데스크톱과 애플리케이션을 최대 4개의 GPU와 단일 워크스테이션에서 16개의 디스플레이로 투명하게 확장하면서 완벽한 성능과 이미지 품질을 제공합니다. 이를 통해 Windows에서는 최대 16K x 16K, Linux에서는 최대 32K x 32K 해상도를 구현할 수 있습니다.
단일 시스템 내에서 두 개의 Sync 보드를 통해 연결된 8개의 GPU를 사용해 최대 32개의 디스플레이의 화면 및 이미지 출력을 동기화할 수 있어, 첨단 영상 시각화 환경을 구현하는 데 필요한 시스템 수를 줄일 수 있습니다.
DisplayPort 2.1b는 DP 또는 HDMI를 사용하여 카드당 최대 4개의 4K 120Hz 디스플레이 또는 DSC와 최대 2개의 8K 60Hz 디스플레이를 지원합니다. *최고의 링크 속도를 위해서는 DP80LL 인증 케이블이 필요합니다.
NVIDIA 앱은 최대 8K의 데스크톱 녹화, 최신 NVIDIA RTX 엔터프라이즈 드라이버 업데이트에 대한 자동 알림, 게임 기능 액세스 등 다양한 생산성 도구를 데스크톱 워크스테이션에 제공합니다.
시스템 가동 시간을 최대화하고, 광범위한 배포를 원활하게 관리하며, 그래픽 및 디스플레이 설정을 원격으로 제어하여 효율적인 운영을 가능하게 합니다.
GPUDirect for Video는 불필요한 시스템 메모리 복사와 CPU 오버헤드를 방지하여 GPU와 비디오 I/O 장치 간의 통신 속도를 높입니다.
C/C++ 및 Fortran과 같은 표준 프로그래밍 언어와 OpenCL, Open ACC, Direct Compute와 같은 API를 기본적으로 실행하여 광선 추적, 비디오 및 이미지 처리, 계산 유체 역학과 같은 기술을 가속화합니다.
Caffe2, MXNet, CNTK, TensorFlow 등과 같은 딥러닝 프레임워크는 훨씬 빠른 학습 시간과 더 높은 다중 노드 학습 성능을 제공합니다. cuDNN, cuBLAS, TensorRT와 같은 GPU 가속 라이브러리는 딥러닝 추론 및 고성능 컴퓨팅(HPC) 애플리케이션 모두에서 더 높은 성능을 제공합니다.
NVWMI은 IT 관리자가 GPU 설정을 구성하고, GPU 정보를 검색하고, 자동화된 작업을 수행하고, 네트워크 전반에 걸쳐 계측 패널을 구축할 수 있는 스크립팅 및 관리 도구입니다.
데스크톱에서 데이터센터에 이르기까지, NVIDIA RTX PRO 6000 Blackwell 시리즈는 IT, 연구자, 엔지니어, 크리에이터를 위해 AI, 과학, 디자인의 경계를 넓히는 탁월한 기능성, 유연성, 확장성을 제공합니다.
RTX PRO Blackwell 6000 시리즈 자세히 보기 >
엔비디아코리아 정품 RTX/QUADRO®는 3년 무상 보증기간 동안 A/S 발생 시 전문 엔지니어의 신속한 원스톱 서비스와 지원을 제공하여 안심하고 제품을 사용할 수 있습니다.
엔비디아코리아 정품 RTX/QUADRO®만을 제공하며 광범위한 제품 포트폴리오와 서버 구축 및 유지보수, 교육 등의 포괄적인 서비스를 제공하여 고객의 비즈니스에 맞춤형 솔루션을 제공합니다.
엔비디아코리아 정품 RTX/QUADRO®는 전문적인 인증 및 워크스테이션 및 서버 OEM의 검증 등을 거쳐 안심하고 최첨단 기능과 성능을 제공합니다.
놀라운 산업 디자인에서 첨단 특수 효과와 복잡한 과학적 시각화에 이르기까지 NVIDIA RTX/ QUADRO®는 세계에서 가장 뛰어난 시각적 컴퓨팅 플랫폼입니다.

병행수입(OEM) GPU 같이 유통과정이 명확하지 않은 경로를 통해서 개별 수입된 제품은 소비자가 구입한 업체(쇼핑몰) 에서만 A/S 및 교환 & 환불이 가능하며, 엔비디아코리아를 통한 정품 A/S 기술 지원 혜택 및 보증을 받을 수 없습니다.
자세히 알아보기 >
A/S 기술 지원 혜택 및 보증 기간은 제품박스와 정품카드, 그래픽카드에 있는 시리얼 넘버 조회를 통해 확인 가능합니다. 리더스시스템즈에 가입 후 시리얼번호 등록 페이지를 통해서 제품 등록 및 보증기간 조회가 가능합니다.
자세히 알아보기 >본 제품의 경우 제조사에서 생산/포장이 이루어진 완제품으로 출고 되므로 정품 박스 개봉 시 (TEAR 라인 개봉) 상품의 가치가 훼손된 것으로 분류되어 교환 및 환불이 불가합니다. 반드시 제품 개봉 전 신중한 구매 확인 및 주문한 상품이 맞는지 확인 부탁드립니다.

2대 이상의 그래픽카드 장착을 검토하시는 고객께서는 쿼드로센터를 통해 장착 호환성 안내를 받으신 후 구매 진행 바랍니다.
쿼드로센터 : 02-6080-8104




| Architecture | NVIDIA Blackwell Architecture |
|---|---|
| Foundry | TSMC |
| Process Size | 4N NVIDIA Custom Process |
| Transistors | 92.2 billion |
| CUDA Parallel Processing cores | 24,064 |
| Tensor Cores | 752 (5th Gen) |
| RT Cores | 188 (4th Gen) |
| Performance |
|
| GPU Memory | 96 GB GDDR7 with ECC |
| Memory Interface | 512-bit |
| Memory Bandwidth | 1792 GB/s |
| Graphics Bus | PCI Express 5.0 x16 |
| Display Connectors | 4x DisplayPort 2.1b |
| Max simultaneous displays |
|
| Multi-Instance GPU | Up to 4x 24 GB | Up to 2x 48 GB | Up to 1x 96 GB |
| NVENC | NVDEC | JPEG | 4x | 4x | 4x |
| Power Consumption | Up to 300W (Configurable) |
| Power Connector | 1x PCIe CEM5 16-pin |
| Thermal Solution | Active |
| NVIDIA® 3D Vision® and 3D Vision Pro | Support via 3-pin mini DIN |
| Frame Lock | Compatible (with NVIDIA RTX PRO Sync) |
| Form Factor | 113 x 267 mm / Full height, Dual Slot / 1.23 kg |
| Die Size | 750 mm2 |
| Graphics APIs | DirectX 12, Shader Model 6.6, OpenGL 4.63, Vulkan 1.33 |
| Compute APIs | CUDA 12.8, OpenCL 3.0, DirectCompute |
| 상품명 | NVIDIA RTX PRO 6000 Blackwell MAX-Q Workstation Edition |
|---|---|
| KC 인증번호 | R-R-NVA-PG153B |
| 정격전압 / 최대소비전력 | 300W |
| 정품 품질 보증 | 3년 무상보증 |
| 출시년월 | 25/03 |
| 제조사 | NVIDIA Corporation |
| 제조국 | - |
| 크기 | 113 x 267 mm / Full height, Dual Slot / 1.23 kg |