제품문의
제품과 관련하여 궁금하신 사항을
문의하기를 통해 해결하세요.
TURING Architecture
GPU Memory 24 GB GDDR6
Memory Bandwidth up to 672 GB/s
Memory Interface 384-bit
72 RT Cores
4608 CUDA Cores
576 Tensor Cores
PCI Express 3.0 x 16
NVIDIA NVLink 100 GB/s
Engines 1x encode, 1x decode
VR Ready


130 TFLOPS의 AI 성능을 구현하는 576개의 NVIDIA Turing 혼합 정밀도 Tensor 코어로 AI 모델을 더 빠르게 트레이닝하십시오. NVIDIA의 CUDA-X AI SDK로 지원(cuDNN, TensorRT 및 15개가 넘는 라이브러리 포함)합니다. 인기 있는 모든 딥 러닝 프레임워크로 작업하고, NGC(NVIDIA GPU Cloud)와 호환이 가능합니다.

엔드 투 엔드 데이터 사이언스 워크플로우를 가속하는 4608개의CUDA 코어로 더 빠르게 작업하십시오. 24GB GDDR6 메모리(또는 NVLink 지원 48GB)로 대용량 데이터 집합을 처리하십시오. NVIDIA CUDA-X AI SDK를 기반으로 개발된 데이터 사이언스용 RAPIDS 라이브러리 제품군으로 지금 시작하십시오. 사용자 PC에서 개발하고 손쉽게 데이터센터로 배포하십시오.

영감이 떠오르는 순간은 기다려주지 않습니다. 거대한 몰입형 세계와 세련된 캐릭터를 구축하고, 다중 애플리케이션 워크플로우를 가속하며, 8K 비디오를 실시간으로 편집하십시오. 24GB 메모리 및 72개의 Turing RT 코어로 초당 11기가레이를 구현하여 사용자는 가장 까다로운 프로젝트를 수행할 수 있습니다.
Turing 아키텍처에는 초당 최대 10기가레이로 빛과 소리가 3D 환경에서 어떻게 이동하는지에 대한 계산을 가속화하는 RT 코어라 불리는 전용 레이 트레이싱 프로세서가 탑재되어 있습니다. Turing은 이전의 Pascal 세대에 비해 실시간 레이 트레이싱을 25배나 빠른 속도로 가속화하며 CPU 보다 30배 이상 빠른 속도로 영화 효과를 위한 최종 프레임 렌더링에 사용될 수 있습니다.
Turing에는 딥 러닝 교육과 추론을 가속화하여 초당 최대 500조 개의 Tensor 작업을 처리하는 프로세서인 새로운 Tensor 코어가 탑재되어 있습니다. 이러한 성능 수준은 노이즈 제거, 해상도 확장, 비디오 재타이밍 등의 AI 향상 기능을 대폭 가속화하여 강력한 새 기능을 갖춘 애플리케이션을 만들어 낼 수 있습니다.
새로운 스트리밍 멀티프로세서 아키텍처가 적용되어 최대 초당 16조 자리의 부동 소수점 연산을 16조 자리의 정수 연산과 병렬 처리할 수 있습니다. 개발자는 NVIDIA의 CUDA 10, FleX 및 PhysX SDK로 최대 4,608개의 CUDA 코어를 활용하여 과학적 시각화, 가상 환경 및 특수 효과를 위한 입자 또는 유체 역학 등의 복잡한 시뮬레이션을 제작할 수 있습니다.
Turing 아키텍처는 향상된 그래픽 파이프라인과 프로그래밍 가능한 새로운 음영 처리 기술로 이전 Pascal 세대보다 훨씬 향상된 래스터 성능을 제공합니다. 이러한 기술에는 대량의 모델 및 장면과 더욱 유연한 상호 작용과 향상된 VR 경험을 제공하는 VRS(Variable Rate Shading), 텍스처 공간 음영 처리, 멀티뷰 렌더링이 포함됩니다.
RTX 기술은 NVIDIA OptiX, Microsoft DXR, Vulkan과 같은 최적화된 광선 추적 API를 통해 실시간 영화 품질 렌더링의 꿈을 실현합니다. 완벽하게 정확한 그림자, 반사 및 굴절을 사용하여 실시간으로 사실적인 개체와 환경을 렌더링 할 수 있는 기능을 통해 이제 아티스트와 디자이너는 그 어느 때보다 빠르게 놀라운 콘텐츠를 만들 수 있습니다.
RTX 플랫폼은 새로운 NVIDIA NGX SDK를 제공하여 강력한 AI 사용 기능을 시각적 애플리케이션에 통합합니다. 이는 지능적인 이미지 조작, 반복 작업의 자동화, 컴퓨팅 집약적 프로세스의 최적화를 통해 시간과 자원을 확보함으로써 아티스트와 디자이너 등의 비주얼 전문가들의 창조력을 극적으로 가속합니다.
사실적인 비주얼을 재현하기 위해서는 동작의 사실적인 표현도 매우 중요합니다. NVIDIA의 PhysX, Flow, FleX, CUDA 코어 및 API의 성능을 갖춘 RTX 플랫폼을 사용하여 게임, 가상 환경, 특수효과 등 모든 분야에서 실제 물체의 동작을 정확하게 모델링 할 수 있습니다.
레이 트레이싱은 가상 3D 장면을 통해 보는 사람의 눈에서 빛이 이동하는 경우 빛이 취할 경로를 추적하여 픽셀의 색상을 계산합니다. 장면을 가로지르는 동안 빛은 다른 물체로 반사하거나 물체에 의해 차단하거나 투명 또는 반투명 물체를 통과할 수 있습니다.


VRS(Variable Rate Shading), 텍스처 공간 음영 처리, 멀티뷰 렌더링 등의 프로그래밍 가능한 음영 처리 분야에서 새로운 발전 기술을 제공합니다. 이로써 대형 모델 및 장면과의 더욱 부드러운 상호 작용과 개선된 VR 환경을 통해 더 풍부한 비주얼을 제작할 수 있습니다.
RTX 지원 GPU는 전용 레이 트레이싱 가속 하드웨어를 포함하고 고급 가속 구조를 사용하며 완전히 새로운 GPU 렌더링 파이프 라인을 구현하여 게임 및 기타 그래픽 애플리케이션에서 실시간 레이 트레이싱을 가능하게 합니다.
그래픽 파이프라인 중 버텍스, 테셀레이션, 지오메트리 쉐이딩 단계에 새로운 쉐이더 모델을 제공하여 지오메트리 연산에 보다 유연하고 효율적으로 접근할 수 있습니다.
텍스처 공간 셰이딩을 사용하면 개체가 메모리에 저장된 개인 좌표공간(텍스처 공간)에서 음영 처리되고 픽셀 셰이더는 결과를 직접 평가하지 않고 해당 공간에서 샘플링합니다.
Variable Rate Shading (VRS)는 프레임의 다른 영역에 대한 음영 비율을 변경하여 렌더링 성능과 품질을 향상시킵니다. VRS 래퍼를 사용하면 개발자가 포비티드 렌더링을 위해 HMD의 시선 추적 기능을 더 쉽게 통합할 수 있으며 이미지 품질 및 성능을 위한 편리한 사전 설정과 맞춤형 구성 지원이 포함됩니다.
Multi-View Rendering (MVR)은 Pascal의 SPS (Single Pass Stereo)를 강력하게 확장합니다. SPS는 X 오프셋을 제외하고 공통된 두 뷰의 렌더링을 허용했지만 MVR에서는 뷰가 완전히 다른 원점 위치 또는 뷰 방향을 기반으로하는 경우에도 단일 패스로 여러 뷰를 렌더링 할 수 있습니다.


가장 큰 장면과 다중 애플리케이션 워크플로우를 위한 맞춤형 메모리를 제공하는 NVIDIA RTX™ 및 NVIDIA Quadro 전문 솔루션으로 가장 복잡한 렌더링 워크로드를 처리하세요. NVIDIA OptiX™ AI 가속화 노이즈 제거 기능으로 복잡한 렌더링 작업을 자동화 및 가속화하고 전문 시각화를 위한 NVIDIA EGX 플랫폼을 통해 데이터센터에 유연한 고성능 렌더링의 성능을 도입하세요.

NVIDIA Iray는 조명과 재료의 실제 동작을 시뮬레이션하여 전문가가 인터랙티브 및 배치 렌더링 워크플로우를 위한 사실적인 이미지를 생성할 수 있도록 해주는 최첨단 렌더링 기술입니다. RTX 하드웨어에 대한 지원은 실시간 레이 트레이싱 및 AI 가속화 노이즈 제거를 제공하여 디자이너와 디지털 아티스트가 시각적으로 놀라운 렌더링을 제작하기 위해 필요한 동시에 워크플로우를 상당히 가속화하는 도구를 제공합니다.

NVIDIA vMaterials는 디자인 및 AEC 워크플로에 사용되는 일반적인 실제 재료를 나타내는 MDL 재료 및 조명의 선별된 컬렉션입니다. Iray 또는 MDL SDK를 통합하면 셰이더를 작성하지 않고도 사용할 준비가 된 수백 가지 재료 라이브러리를 애플리케이션에 빠르게 가져올 수 있습니다. 재료는 일관된 스케일로 제작되므로 설계자는 스케일을 다시 조정할 필요 없이 재료에서 재료로 쉽게 전환할 수 있습니다.
TITAN RTX는 ResNet-50 및 GNMT Titan과 같은 고급 모델을 TITAN XP보다 최대 4배 빠르게 트레이닝합니다. 또한, RAPIDS 는 CPU보다 최대 3배 빠르게 모델을 트레이닝합니다. 다중 정밀도 Turing Tensor 코어를 기반으로 개발된 TITAN RTX는 FP32, FP16, INT8 및 INT4에서 획기적인 성능을 지원하여 더 빠른 트레이닝 및 신경망 추론을 실현합니다. 이전 세대 TITAN GPU 및 NVIDIA NVLink™ 메모리 용량의 2배를 탑재한 TITAN RTX를 사용하여 연구자 및 데이터 과학자는 모든 GPU 메모리에서 거대 신경망 및 데이터 집합을 실험할 수 있습니다.

Pytorch을 활용한 GNMT 트레이닝 | NGC 컨테이너 19.01 | Titan XP BS=128 | Titan RTX BS=384

MXNet을 활용한 ResNet-50 트레이닝 | NGC 컨테이너 18.11 | Titan XP BS=96 | Titan RTX BS=256

CPU: Core i9 | 엔드 투 엔드 시간 = 데이터 준비 + 전환 + 트레이닝 + 인증


TITAN RTX는 72개의 Turing RT 코어와 24GB의 메모리를 사용해 초대형 모델을 렌더링하고 실시간 8K 영상 편집을 지원하며 복잡한 멀티 어플리케이션 워크플로우를 실행하여 원활한 경험을 제공합니다.

Autodesk Maya 2019、Adobe Photoshop CC 2019, 그리고 Allegorithmic Substance Painter 2019의 3D 시각화 멀티 앱 작업 과정에서 TITAN RTX 및 RTX 2080 Ti의 초당 프레임 수

NVIDIA TITAN RTX NVLink 브릿지는 100 GB/s 인터페이스를 통해 2장의 TITAN RTX 카드를 연결합니다. 결과적으로 메모리 용량을 48GB까지 효과적으로 두 배 늘릴 수 있기 때문에 뉴럴 네트워크를 더욱 빨리 트레이닝하고 더 큰 데이터 세트를 처리하여 가장 큰 렌더링 모델로 작업할 수 있습니다.




 2X 8-pin Power Conncetor
2X 8-pin Power Conncetor
| Architecture | Turing |
|---|---|
| GPU Memory | 24 GB GDDR6 |
| Clock | 1350 MHz Base Clock / 1770 MHz Boost Clock / 7000 MHz Memory Clock |
| Core |
|
| Memory Data Rate | 14 Gbps |
| L2 Cache Size | 6144 K |
| Graphics Processing Clusters | 6 |
| Texture Processing Clusters | 36 |
| Streaming Multiprocessors | 72 |
| Memory Interface | 384-bit |
| Total Memory Bandwidth | 672 GB/s |
| Texture Rate (Bilinear) | 510 GigaTexels/sec |
| Fabrication Process | 12 nm FFN |
| Transistor Count | 18.6 Billion |
| Thermal Threshold | 89° C |
| Power Connectors | Two 8-pin |
| Form Factor | Dual Slot |
| Thermal Design Power (TDP) | 280 Watts |
| Recommended Power Supply | 650 Watts |
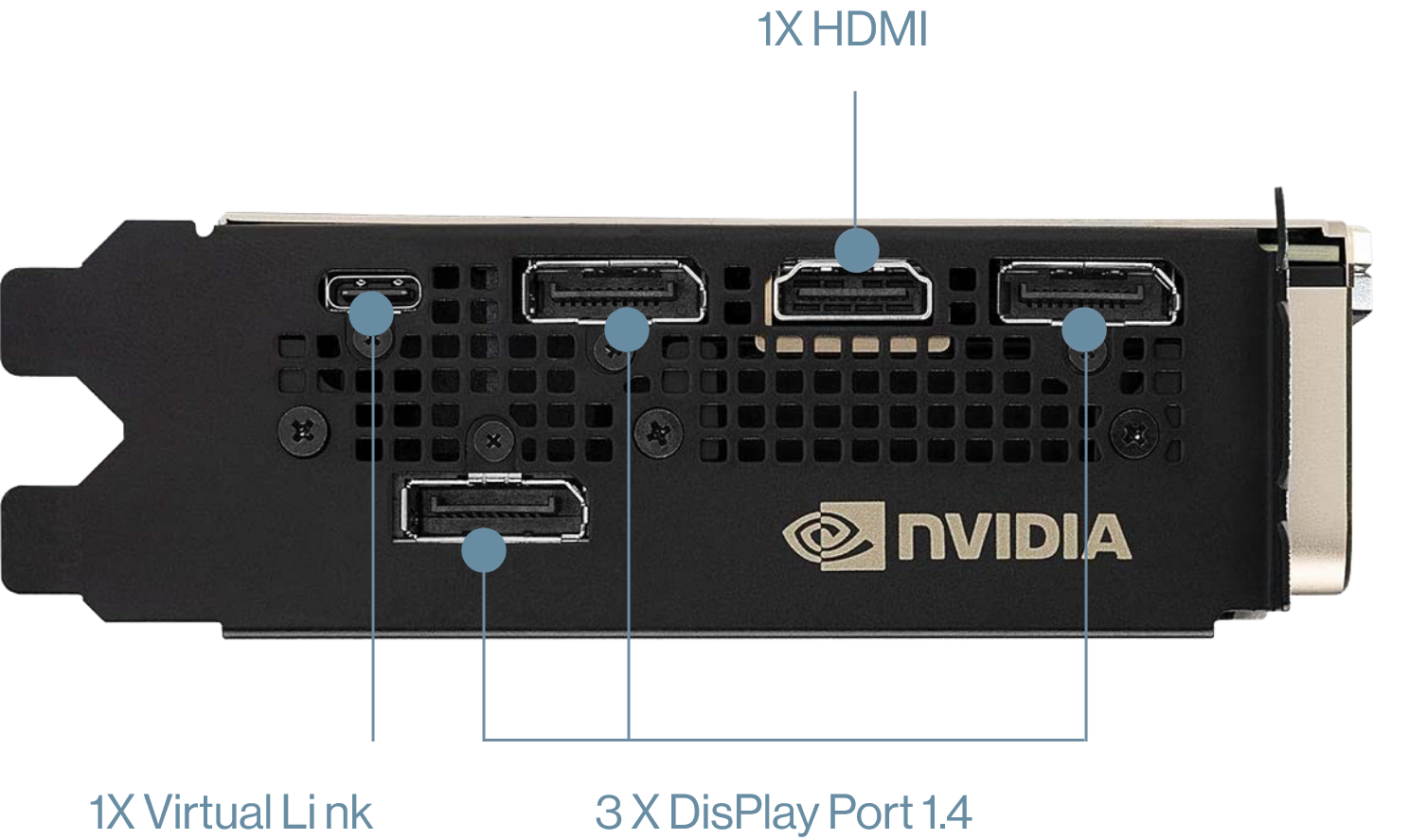
| Connectors | 3 x DisplayPort, 1 x HDMI, 1 x USB Type-C |
| OS Certification | Windows 7 64-bit, Windows 10 64-bit, Linux 64-bit |
| 상품명 | NVIDIA TITAN RTX |
|---|---|
| KC 인증번호 | R-R-NVA-PG150 |
| 최대소비전력 | 280 W |
| 정품 품질 보증 | 3년 무상보증 |
| 출시년월 | 2018/12 |
| 제조사 | NVIDIA Corporation |
| 제조국 | China |
| 폼 팩터 | Dual Slot |