- NVIDIA Technology
NVIDIA Ampere Architecture - NVIDIA Technology
CUDA-X - NVIDIA Technology
NVLink / NVSwitch - NVIDIA Technology
NVIDIA RTX
세계 최고 성능과 탄력성을 갖춘 데이터센터 AI 및
HPC의 핵심 NVIDIA Ampere 아키텍처
과학자, 연구원, 엔지니어들은 AI와 고성능 컴퓨팅(HPC)을 통해 세계에서 가장 중요한 과학, 산업, 빅 데이터 과제를 해결하려 노력하고 있습니다.
한편, 엔터프라이즈는 AI의 성능을 활용하여 온프레미스 및 클라우드 모두에서 대규모 데이터세트로 부터 새로운 인사이트를 끌어내려고 하고 있습니다.
탄력적인 컴퓨팅의 시대에 설계된 NVIDIA Ampere 아키텍처는 모든 규모에서 비교할 수 없는 가속화를 제공하여 또 한 번의 거대한 도약을 실현합니다.

3세대 Tensor 코어
- Tensor Core는 하드웨어, 네트워킹, 소프트웨어, 라이브러리를 NGC™의 최적화된 AI 모델 및 애플리케이션과 통합하는 완전한 NVIDIA 데이터센터 솔루션의 필수적인 구성 요소입니다. 연구원은 가장 강력한 엔드 투 엔드 AI 및 HPC 플랫폼을 통해 실제 결과를 제공하고 솔루션을 규모에 맞게 프로덕션에 배포할 수 있습니다. NVIDIA Ampere 아키텍처는 새로운 정밀도인 Tensor Float 32(TF32) 및 부동 소수점 정밀도 64(FP64)를 도입해 이러한 혁신을 토대로 구축되어 AI 채택을 가속화 및 단순화하고 Tensor 코어의 성능을 HPC로 확장합니다.
- TF32는 아무런 코드 변경 없이 AI를 최대 20배로 가속하면서 FP32와 마찬가지로 작동합니다. NVIDIA 자동 혼합 정밀도를 사용하면 연구원들은 단 몇 줄의 코드를 추가하여 자동 혼합 정밀도 및 FP16을 통해 추가적으로 2배의 성능을 얻을 수 있습니다. 또한 NVIDIA Ampere 아키텍처 Tensor 코어 GPU의 Tensor 코어는 bfloat16, INT8 및 INT4 지원으로 AI 트레이닝과 추론 모두에 놀랍도록 다재다능한 가속기를 생성합니다. A100 및 A30 GPU의 경우 Tensor 코어의 성능을 HPC에 도입하여 완전하고 IEEE 인증을 받은 FP64 정밀도로 매트릭스 연산을 지원합니다.
FP64 Tensor Core

Tensor Float 32

Tensor Float 32

INT8 Precision

| NVIDIA A100 | NVIDIA Turing | NVIDIA Volta | |
|---|---|---|---|
| 지원되는 Tensor 코어 정밀도 | FP64, TF32, bfloat16, FP16, INT8, INT4, INT1 | FP16, INT8, INT4, INT1 | FP16 |
| 지원되는 CUDA® Core 코어 정밀도 | FP64, FP32, FP16, bfloat16, INT8 | FP64, FP32, FP16, INT8 | FP64, FP32, FP16, INT8 |
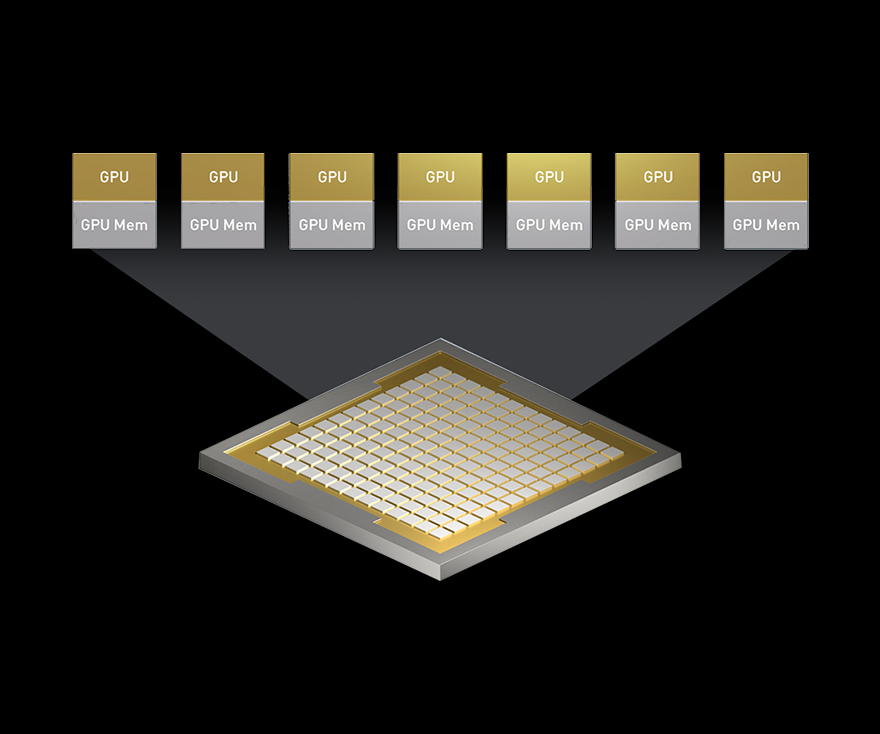
- MIG(Multi-Instance GPU)
- 모든 AI 및 HPC 애플리케이션은 가속의 이점을 얻을 수 있지만 모든 애플리케이션에 GPU의 전체 성능이 필요한 것은 아닙니다. MIG는 A100 및 A30 GPUs GPU에서 지원되는 기능으로, 워크로드가 GPU를 공유할 수 있도록 합니다. MIG를 통해 각 GPU은 자체 고대역폭 메모리, 캐시, 컴퓨팅 코어로 하드웨어 수준에서 완전히 격리되고 보호되는 여러 개의 GPU 인스턴스로 분할될 수 있습니다. 이제 개발자는 크고 작은 모든 응용 프로그램을 획기적으로 가속화할 수 있으며 보장된 서비스 품질을 경험할 수 있습니다. 그리고 IT 관리자는 최적화된 활용을 위한 적절한 규모의 GPU 가속화를 제공할 수 있으며 베어 메탈 및 가상화된 환경 전반에서 모든 사용자와 애플리케이션으로 액세스를 확장할 수 있습니다.

- 3세대 NVLink
- NVIDIA Ampere 아키텍처의 3세대 NVIDIA® NVLink®는 GPU 간의 직접적인 대역폭을 2배인 600GB/s로 증가시키며 이는 PCIe Gen4의 10배에 달합니다. 최신 세대의 NVIDIA NVSwitch™와 연결되면 서버의 모든 GPU는 서로 간에 최대 NVLink 속도로 통신하며 데이터를 놀랍도록 빠르게 전송할 수 있습니다. NVIDIA DGX™A100 및 다른 주요 컴퓨터 제조사의 서버는 NVLink와 NVSwitch 기술을 NVIDIA HGX™ A100 베이스보드로 활용하여 HPC 및 AI 워크로드에 더 높은 확장성을 제공합니다.
- 구조적 희소성
- 최신 AI 네트워크는 매개변수가 수백만 개, 일부 경우에는 수십억 개에 달하는 대규모로, 점점 더 규모가 커지고 있습니다. 정확한 예측과 추론에 매개변수가 모두 필요한 것은 아니므로, 일부는 정확성 감소 없이 모델을 희소하게 만들기 위해 0으로 변환할 수 있습니다. Tensor 코어는 희소한 모델에 대해 최대 2배 높은 성능을 제공할 수 있습니다. 희소성 기능은 AI 추론에 더 수월하게 이점을 제공하지만, 모델 트레이닝의 성능을 개선하는 데 사용할 수도 있습니다.
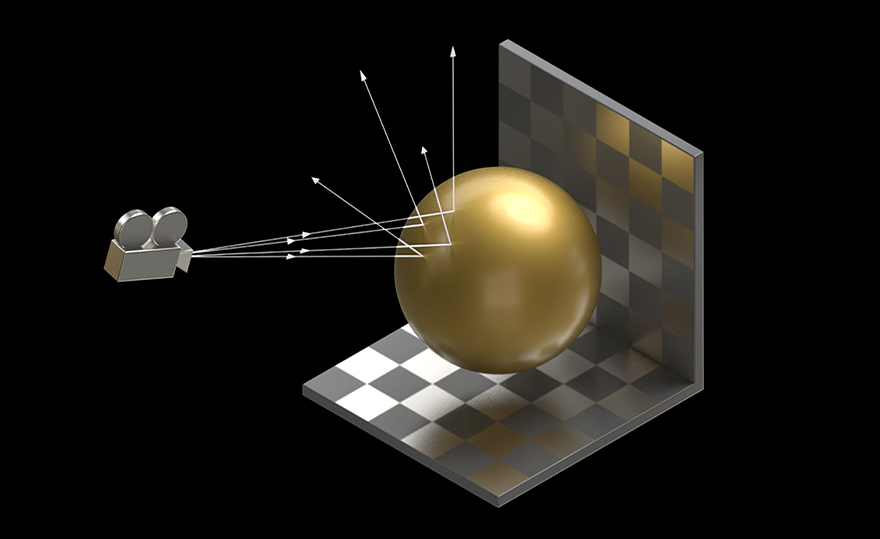
- 2세대 RT 코어
- NVIDIA Ampere 아키텍처 2세대 RT 코어는 영화 콘텐츠의 사실적인 렌더링, 건축 디자인 평가, 제품 디자인의 가상 프로토타입 제작과 같은 워크로드에 엄청난 속도 향상을 제공합니다. RT 코어는 또한 시각적 정확도가 더 뛰어난 결과를 더 빠르게 제공하기 위해 레이 트레이싱 처리된 모션 블러의 렌더링 속도를 향상하며, 고급 음영 처리 또는 노이즈 제거 기능과 함께 레이 트레이싱을 동시에 실행할 수 있습니다.
데이터 사이언스와 AI를 위한
NVIDIA GPU 가속화 라이브러리
데이터 사이언스는 AI의 주요 동력 중 하나이며 AI는 모든 산업을 혁신할 수 있습니다. 그러나 이러한 성능을 활용하는 것은 복잡한 문제입니다. AI 기반 애플리케이션을 개발하는 데는 데이터 처리, 기능 엔지니어링, 머신 러닝, 확인 및 배포 등 여러 단계가 필요하고 각 단계마다 대용량 데이터 처리와 방대한 컴퓨팅 작업이 포함됩니다. 이에는 가속화 컴퓨팅이 필요하고 바로 이 부분이 CUDA-X AI가 혁신을 주도하는 분야입니다.

- 최신 AI 애플리케이션을 위한 가속화
- 데이터 사이언스 워크플로우에는 모든 과정에 걸쳐 강력한 컴퓨팅 기능이 필요합니다. NVIDIA CUDA-X AI는 딥 러닝, 머신 러닝 및 HPC를 위한 필수 최적화를 제공하고 있는 NVIDIA의 획기적인 병렬 프로그래밍 모델 CUDA® 위에 구축된 소프트웨어 가속화 라이브러리 컬렉션으로 NVIDIA CUDA-X AI 라이브러리에는 딥 러닝 기초 요소를 위한 cuDNN, 데이터 사이언스 워크플로우, 머신 러닝 알고리즘 가속화를 위한 cuML, 추론하기 위해 학습 모델 최적화를 위한 NVIDIA® TensorRT™, Pandas와 유사한 데이터 과학용 API를 액세스하기 위한 cuDF, 그래프에서 고성능 분석을 수행하기 위한 cuGraph 및 13개 이상의 기타 라이브러리가 포함됩니다. 이들은 NVIDIA Tensor Core GPU와 함께 원활하게 작동하여 AI 기반 애플리케이션의 개발 및 배포를 가속화합니다. CUDA-X AI는 지속적인 애플리케이션 성능 향상을 활용하는 동시에 생산성을 높일 힘을 개발자에게 제공합니다.

- 어디에서나 사용 가능
- CUDA-X AI는 광범위하게 사용 가능합니다. 소프트웨어 가속화 라이브러리는 TensorFlow, PyTorch, MXNet 및 RAPIDS와 같은 인기 있는 데이터 과학 소프트웨어를 포함하는 모든 딥 러닝 프레임워크로 통합됩니다. 이 프레임워크는 AWS, Microsoft Azure 및 Google Cloud를 포함하는 클라우드 플랫폼 선두주자의 일부입니다. 이들은 개별 다운로드 또는 NGC의 컨테이너화된 소프트웨어 스택으로 무료입니다. CUDA-X AI 라이브러리는 데스크톱, 워크스테이션, 서버, 클라우드 컴퓨팅 및 IoT(사물인터넷) 장치를 포함하여 NVIDIA GPU상 어디에나 배포할 수 있습니다. 새 애플리케이션을 제작하든 기존 애플리케이션의 속도를 높이려 하든 CUDA-X AI는 가장 효율적이고 효과적인 경로를 제공합니다.
강력한 엔드 투 엔드 컴퓨팅 플랫폼을 구축을 위한
향상된 속도와 확장된 상호 연결을 지원합니다.
AI 및 고성능 컴퓨팅(HPC)에서의 컴퓨팅 수요가 증가함에 따라 GPU 시스템이 함께 하나의 거대한 가속기 역할을 할 수 있도록 GPU 간의 원활한 연결이 가능한 멀티 GPU 시스템에 대한 필요성이 커지고 있습니다. 하지만 표준인 PCIe의 제한된 대역폭으로 인해 병목 현상이 발생하는 경우가 잦습니다. 가장 강력한 엔드 투 엔드 컴퓨팅 플랫폼을 구축하려면 속도와 확장성이 더욱 향상된 상호연결이 필요합니다.

NVLink GPU 간 연결을 지원하는 NVIDIA H100 PCIe

NVLink GPU 간 연결을 지원하는 NVIDIA H100 PCIe
- NVIDIA NVLINK를 통한 시스템 처리량 극대화
- 4세대 NVIDIA® NVLink® 기술은 멀티 GPU 시스템 구성에 1.5배 높은 대역폭과 향상된 확장성을 제공합니다. 하나의 NVIDIA H100 Tensor 코어 GPU는 최대 18개의 NVLink 연결을 지원하여 900GB/s의 총 대역폭을 구현하며, 이는 PCIe Gen5의 최대 7배 이상입니다. NVIDIA DGX™ H100과 같은 서버는 이 기술을 활용하여 초고속 딥 러닝 트레이닝을 위한 더 높은 확장성을 제공합니다.
- NVLINK 성능
- NVIDIA H100의 NVLink는 GPU 간 통신 대역폭을 기존 세대 대비 1.5배로 확장하므로 연구원들은 복잡한 문제의 해결을 위해 더 크고 정교한 애플리케이션을 사용할 수 있습니다.

NVIDIA NVLink & NVSwitch
02:08
- NVIDIA NVSWITCH로 GPU 완전히 연결
- 3세대 NVIDIA NVSwitch™는 NVLink의 고급 통신 기능을 구축하여 컴퓨팅 집약적 워크로드에 더 높은 대역폭과 지연 시간 절감을 제공합니다. 고속의 집합 연산을 지원하기 위해 각각의 NVSwitch에는 네트워크 내 감소 및 멀티 캐스트 가속화를 위한 NVIDIA SHARP(Scalable Hierarchical Aggregation Reduction Protocol)™용 엔진이 장착된 64개의 NVLink 포트가 있습니다.

- NVLink NVSWITCH가 함께 작동하는 방식
- NVLink는 서버 내의 멀티 GPU 입출력(IO)을 확장하는 GPU 간 직접 상호 연결입니다. NVSwitch는 여러 NVLink를 연결하여 단일 노드 및 노드 간 전체 NVLink 속도에서 올 투 올 GPU 통신을 제공합니다. NVIDIA는 NVLink와 NVSwitch를 결합하여 최초의 산업 전반 AI 벤치마크인 MLPerf 1.1을 획득했습니다.

- NVIDIA NVLink SWITCH
- NVIDIA NVLink Switch는 128개의 NVLink 포트를 갖추고 있으며 25.6테라비트/초(Tb/s)의 논블로킹 스위칭 용량을 갖추고 있습니다. 랙 스위치는 외부 4세대 NVLink 접속을 지원하는 NVIDIA DGX 및 NVIDIA HGX™ 시스템에서 고대역폭과 짧은 레이텐시를 제공하도록 설계되었습니다.
- 비교할 수 없는 성능을 제공하는 완전한 연결
- NVSwitch는 단일 서버 노드에서 8개~16개의 완전히 연결된 GPU를 지원하는 최초의 노드 간 스위치 아키텍처입니다. 3세대 NVSwitch는 놀라운 900GB/s의 속도로 모든 GPU 쌍을 상호 연결합니다. 완전한 올 투 올 커뮤니케이션을 지원합니다. GPU는 최대 15 페타플롭스의 딥 러닝 컴퓨팅 성능을 갖춘 단일 고성능 가속기로 사용할 수 있습니다.
- 가장 강력한 AI 및 HPC 플랫폼
- NVLink 및 NVSwitch는 완전한 NVIDIA 데이터센터 솔루션의 필수 구성 요소로, 해당 솔루션은 NVIDIA AI Enterprise 소프트웨어 제품군과 NVIDIA NGC™ 카탈로그의 하드웨어, 네트워킹, 소프트웨어, 라이브러리 및 최적화된 AI 모델 및 애플리케이션을 통합합니다. 연구원은 가장 강력한 엔드 투 엔드 AI 및 HPC 플랫폼을 통해 실제 결과를 제공하고 솔루션을 프로덕션에 배포하여 모든 규모의 전례 없는 가속화를 제공할 수 있습니다.
| 2세대 | 3세대 | 4세대 | |
|---|---|---|---|
| 총 NVLink 대역폭 | 300GB/s | 600GB/s | 900GB/s |
| GPU별 최대 연결 수 | 6 | 12 | 18 |
| 지원되는 NVIDIA 아키텍처 | NVIDIA Volta™ 아키텍처 | NVIDIA Ampere 아키텍처 | NVIDIA Hopper™ 아키텍처 |
| 1세대 | 2세대 | 3세대 | |
|---|---|---|---|
| 직접 연결/노드를 지원하는 GPU 수량 | 최대 8개 | 최대 8개 | 최대 8개 |
| NVSwitch GPU 간 대역폭 | 300GB/s | 600GB/s | 900GB/s |
| 총 집계 대역폭 2.4TB/s | 2.4TB/s | 4.8TB/s | 7.2TB/s |
| 지원되는 NVIDIA 아키텍처 | NVIDIA Volta™ 아키텍처 | NVIDIA Ampere™ 아키텍처 | NVIDIA Hopper™ 아키텍처 |
| 서버 간 NVLink 및 NVSwitch | |
|---|---|
| 직접 연결/노드를 지원하는 GPU 수량 | 최대 256개 |
| NVSwitch GPU 간 대역폭 | 900GB/s |
| 총 집계 대역폭 2.4TB/s | 57.6TB/s |
| 인 네트워크 감소 | NVSwitch의 SHARP 감소 |
| 핵심 소프트웨어 지원 | CUDA®, CUDA-X™, Magnum IO™ |
| 지원되는 NVIDIA 아키텍처 | NVIDIA Hopper 아키텍처 |
전문가를 위한 최고의 작업환경과 관리를 위한
가속화된 비주얼 컴퓨팅 플랫폼 NVIDIA® RTX™
획기적인 건축 및 산업 디자인부터 첨단 특수 효과와 복잡한 과학적 시각화까지 모두 아우르는 NVIDIA® RTX™는 세계 최고의 전문 비주얼 컴퓨팅 플랫폼입니다. 수백만 명에 이르는 크리에이티브 및 기술 사용자들에 의해 워크플로우를 가속화할 수 있는 제품으로 신뢰받고 있는 NVIDIA RTX 및 NVIDIA Quadro® 전문 솔루션은 오늘날의 엄청난 도전 과제를 미래의 비즈니스 성공으로 전환할 수 있습니다.


- 광선추적 (Ray tracing)
- RTX 기술은 NVIDIA OptiX ™ , Microsoft DXR 및 Vulkan 과 같은 최적화된 레이 트레이싱 API를 통해 실시간 영화 품질 렌더링의 꿈을 실현합니다. 완벽하게 정확한 그림자, 반사 및 굴절을 사용하여 사실적인 개체와 환경을 실시간으로 렌더링하는 기능을 통해 이제 아티스트와 디자이너는 그 어느 때보다 빠르게 놀라운 콘텐츠를 제작할 수 있습니다.
- 인공 지능 (AI)
- NVIDIA RTX 기술은 비주얼 컴퓨팅에 AI의 힘을 제공하여 개발자가 최종 사용자에게 전례 없는 워크플로 가속화를 제공하는 AI 증강 애플리케이션을 만들 수 있도록 합니다. 이것은 이미지의 지능적인 조작, 반복적인 작업의 자동화, 컴퓨팅 집약적인 프로세스의 최적화를 통해 시간과 자원을 확보함으로써 아티스트와 디자이너의 창의성을 극적으로 가속화합니다.

- 래스터화
- RTX 기술은 가변 속도 셰이딩, 텍스처 공간 셰이딩 및 멀티뷰 렌더링과 같은 프로그래밍 가능한 셰이딩의 발전을 특징으로 합니다. 이를 통해 대형 모델 및 장면과의 보다 유연한 상호 작용과 향상된 VR 경험을 통해 보다 풍부한 시각 효과를 생성할 수 있습니다.

- 시뮬레이션
- 실물과 같은 비주얼은 외형뿐만 아니라 동작 방식의 결과입니다. NVIDIA PhysX®, Flow, FleX 및 CUDA와 같은 CUDA® 코어 및 API 의 성능으로 RTX 기술은 게임에서 가상 환경 및 특수 효과에 이르기까지 모든 분야에서 실제 개체의 동작을 정확하게 모델링 할 수 있습니다.
빛의 물리적 동작을 시뮬레이션하는 NVIDIA 실시간 레이 트레이싱은
아름다움과 완벽한 현실감을 가능하게 하고 기존 개발 파이프라인에 쉽게 맞습니다.

- RTX 글로벌 일루미네이션
- 베이킹 시간, 빛 누출 또는 값비싼 프레임당 비용이 없는 다중 바운스 간접 조명, RTX Global Illumination(RTXGI)은 엄격한 프레임 예산에서도 실시간으로 무한 바운스 조명을 지원하는 확장 가능한 솔루션입니다. 실시간 엔진 내 조명 업데이트를 통해 빛의 속도로 콘텐츠 제작을 가속화하고 모든 DXR(DirectX Raytracing) 지원 GPU에서 광범위한 하드웨어 지원을 즐기십시오. RTXGI는 RTXDI(RTX Direct Illumination)와 결합하여 무제한의 동적 광원으로 완전히 광선 추적된 장면을 생성하도록 제작되었습니다.

- RTX 직접 조명
- RTX Direct Illumination을 사용하여 완전히 레이 트레이싱된 수백만 개의 동적 조명을 생성할 수 있습니다. 실시간 레이 트레이싱 SDK인 RTXDI는 100,000에서 수백만 개의 영역 조명을 계산해야 하는 야간 및 실내 장면의 사실적인 조명을 제공합니다. 더 이상 베이킹, 더 이상 영웅 조명이 없습니다. 픽셀당 광선 수가 제한되어도 무한한 창의성을 발휘할 수 있습니다. RTXGI 및 NVIDIA NRD(Real-Time Denoiser)와 통합하면 낮이나 밤에 환경이 실내이든 실외이든 상관없이 장면에 숨막히고 확장 가능한 레이 트레이싱 조명과 선명한 노이즈 제거 이미지의 이점이 있습니다.
RTX Boulevard - Direct Illumination Demo
01:20
- 딥 러닝 슈퍼 샘플링 NVIDIA DLSS
- AI 기반 프레임 속도 부스트는 동급 최고의 이미지 품질을 제공합니다. NVIDIA DLSS(Deep Learning Super Sampling)는 NVIDIA 슈퍼컴퓨터에서 훈련된 일반화된 딥 러닝 네트워크를 사용하여 RTX GPU에서 Tensor Core의 성능을 활용하여 저해상도 입력을 고해상도 출력으로 업스케일링하고 선명하게 합니다. 그 결과 해상도와 광선 추적 설정을 최대화할 수 있는 헤드룸과 타의 추종을 불허하는 성능이 제공됩니다.

- NVIDIA 실시간 디노이저
- 고품질 실시간 노이즈 제거 기능은 레이 트레이싱된 장면에서 최고 품질의 사진을 제공합니다. NVIDIA Real-Time Denoiser는 1/2에서 1개의 RPP(ray-per-pixel) 신호와 함께 작동하도록 설계된 유일한 종류의 노이즈 제거기입니다. NRD는 렌더 입력과 환경 이미지를 사용하여 실제와 유사한 결과를 제공하므로 하드웨어로 인해 RPP 예산이 얼마나 빠듯한지 상관없이 전체 RTX 기술 제품군을 켤 수 있습니다.
NVIDIA RTX 아키텍쳐

- 텐서 코어
- Tensor Core는 NVIDIA 하드웨어에서 AI를 활성화합니다. DLSS를 통한 업스케일링 및 샤프닝에 활용되어 딥 러닝 기반 슈퍼 샘플링 없이는 달성할 수 없는 성능 향상 및 이미지 품질을 제공합니다.
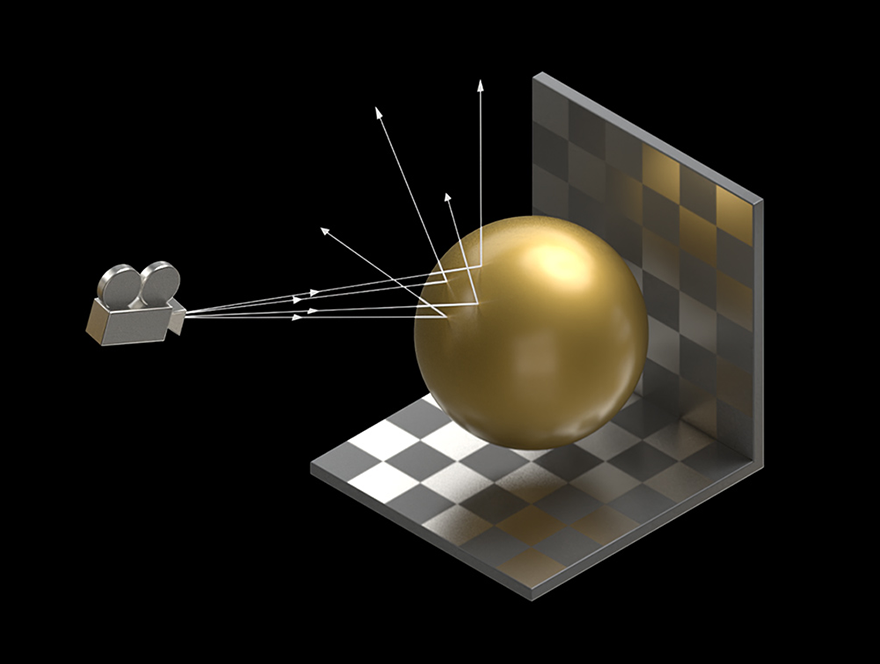
- RT 코어
- RT 코어는 탁월한 효율성으로 광선 추적 작업을 수행하는 데 전념하는 가속기 장치로 NVIDIA RTX 소프트웨어와 RT 코어의 결합을 통해 물리적으로 정확한 조명으로 사실적인 개체와 환경을 만들 수 있습니다.
콘텐츠 제작자와 게임 개발자에게 영화와 같은 품질의
실시간 렌더링을 제공하는 RTX 레이 트레이싱 API

고급 디스플레이 기술에서 최적으로 조정된 드라이버에 이르기까지
워크플로우를 향상시키는 다양한 독점 기능을 활용하세요.
- 멀티 디스플레이
- 다중 8K 모니터, 베젤 보정 기능이 있는 NVIDIA Mosaic 다중 디스플레이 기술, NVIDIA의 Warp 및 Blend SDK 지원을 통해 가상 프로덕션을 위한 대규모 CAVE 환경, 비디오 월, 위치 기반 엔터테인먼트 배포 및 LED 볼륨을 구축 하십시오.
- 생산성 도구
- 4K 기록, 드라이버 업데이트 자동 알림 및 게임 기능을 포함한 모든 생산성 툴 제품군을 얻을 수 있습니다. 또한 NVIDIA RTX Desktop Manager 소프트웨어를 사용하면 유연한 창 스냅, 사용자 프로필, 창 관리 및 핫키 지원을 포함한 전체 디스플레이 관리 툴 제품군에 액세스하여 데스크톱을 관리할 수 있습니다.
- Quadro Sync
- NVIDIA Quadro Sync로 여러 NVIDIA RTX 또는 NVIDIA Quadro 그래픽 카드를 디스플레이 또는 프로젝터와 동기화 하여 이전에는 볼 수 없었던 대규모 시각화를 생성합니다.
- 엔터프라이즈 드라이버
- 소프트웨어 호환성에 대해 지속적으로 조정되고 테스트되는 NVIDIA RTX Enterprise/Quadro Drivers를 통해 100개 이상의 전문 애플리케이션에서 성능을 최적화하여 최고의 시스템 성능을 제공합니다.
- Video Encode and Decode
- 전용 비디오 인코딩 및 디코딩 엔진으로 멀티스트림 비디오 애플리케이션에 필요한 성능과 보안을 확보하십시오.
- 실시간 스트리밍 및 영상 통화
- 홈 오피스를 개인 스튜디오로 바꾸세요. NVIDIA 브로드캐스트 앱은 노이즈 제거 및 가상 배경과 같은 강력한 AI 효과를 사용하여 화상 회의 통화, 음성 채팅 및 라이브 스트림을 업그레이드 합니다.