
리더스시스템즈에서 제공하는 데이터 센터를 위한 맞춤형 솔루션
-
워크스테이션 딥 러닝 솔루션
딥 러닝 워크스테이션 솔루션을 통해 작업 공간에서 편리하게 AI 슈퍼 컴퓨팅 성능을 활용하고 NGC에서 필요한 모든 딥 러닝 소프트웨어를 사용할 수 있습니다. 이제 딥 러닝을 필요로 하는 누구든지 데스크 사이드 딥 러닝을 시작할 수 있습니다.
-
GPU 클라우드 컴퓨팅 솔루션
모든 엔터프라이즈에서 물리적 데이터센터를 구축할 필요 없이 손쉽게 대규모 컴퓨팅 성능에 액세스할 수 있습니다. AI, 고성능 컴퓨팅(HPC) 및 의료 영상 활용, 차세대 그래픽 기술 적용 등 워크로드 전반에서 최고 성능을 경험할 수 있습니다.
-
온 프레미스 가속 컴퓨팅 솔루션
GPU 가속 데이터센터는 원하는 규모와 더 적은 수의 서버로 컴퓨팅 및 그래픽 워크로드에 혁신적인 성능을 제공하여 더 빠르게 정보를 얻고 비용을 획기적으로 절감할 수 있습니다. 가장 복잡한 딥 러닝 모델을 트레이닝하여 가장 심각한 문제를 해결하세요.
-
엣지 컴퓨팅 솔루션
현대 기업은 이제 수 십억 개의 IoT 센서를 통해 생성 된 데이터를 활용해 더 빠른 통찰력과 시간과 비용 절감을 할 수 있습니다. 실시간으로 결정을 내리고 강력하고 분산 된 컴퓨팅과 안전하고 간단한 원격 관리 및 업계 최고 기술과의 호환성을 기대할 수 있습니다.
더 높은 성능과 더 빠른 메모리, 컴퓨팅 효율성을 위한 방대한 대역폭
NVIDIA GH200 Grace Hopper ™ 슈퍼칩은 대규모 AI 및 고성능 컴퓨팅 (HPC) 애플리케이션을 위해 처음부터 설계된 혁신적인 프로세서입니다. 이 슈퍼칩은 테라바이트급 데이터를 처리하는 애플리케이션에서 최대 10배 더 높은 성능을 제공하여 과학자와 연구자들이 세계에서 가장 복잡한 문제에 대한 전례 없는 해결책을 찾을 수 있도록 지원합니다.

NVIDIA GH200 Grace Hopper Superchip
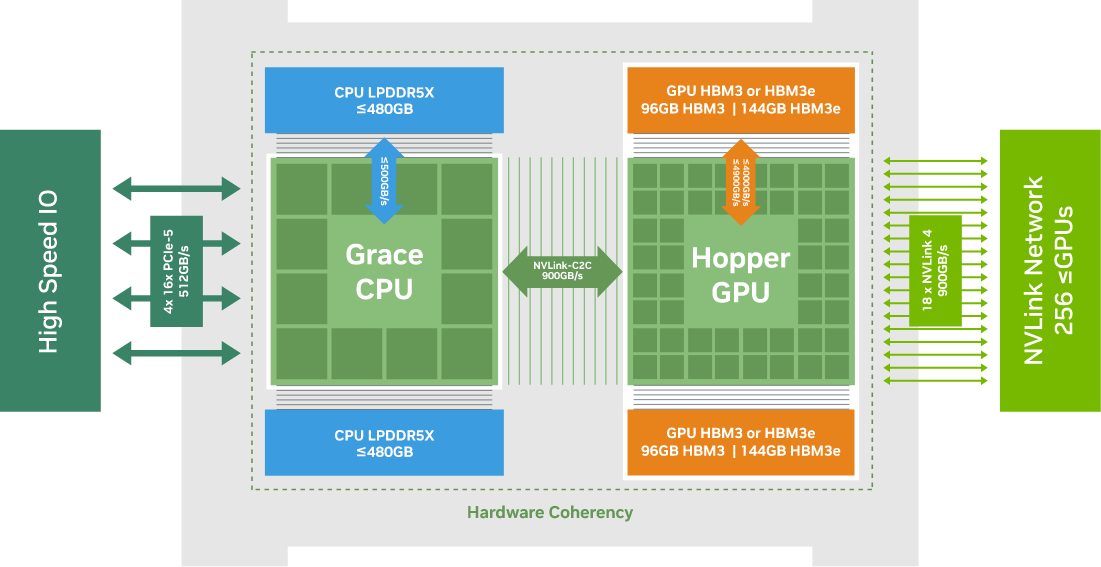
GH200 Grace Hopper 슈퍼칩은 NVIDIA NVLink™-C2C를 사용하여 NVIDIA Grace™ 및 Hopper™ 아키텍처를 결합하여 가속 AI 및 HPC 애플리케이션을 위한 CPU+GPU 코히어런트 메모리 모델을 제공합니다. 900GB/s의 코히어런트 인터페이스를 갖춘 이 슈퍼칩은 PCIe Gen5보다 7배 빠릅니다. 또한 HBM3 및 HBM3e GPU 메모리를 통해 가속 컴퓨팅 및 생성 AI를 강화합니다. GH200은 NVIDIA AI Enterprise, HPC SDK, Omniverse™를 포함한 모든 NVIDIA 소프트웨어 스택과 플랫폼을 실행합니다.

NVIDIA GH200 NVL2
모델의 복잡성이 폭발적으로 증가함에 따라 AI의 요구 사항을 충족하기 위해 가속 컴퓨팅과 에너지 효율성이 매우 중요해지고 있습니다. NVIDIA Grace™ CPU는 독보적인 성능과 효율성을 제공하는 획기적인 Arm® CPU입니다. GPU와 긴밀하게 결합되어 가속 컴퓨팅을 강화하거나 강력하고 효율적인 독립형 CPU로 배포할 수 있습니다.
HPC 및 AI 워크로드를 위한 동급 최고의 성능
GH200 Grace Hopper Superchip은 HPC 및 AI 워크로드를 위한 최초의 진정한 이기종 가속 플랫폼입니다. GPU와 CPU의 강점을 모두 갖춘 모든 애플리케이션을 가속화하는 동시에 지금까지 가장 간단하고 생산적인 이기종 프로그래밍 모델을 제공하여 과학자와 엔지니어가 세계에서 가장 중요한 문제를 해결하는 데 집중할 수 있도록 합니다. AI 추론 워크로드의 경우 GH200 Grace Hopper Superchip은 NVIDIA 네트워킹 기술과 결합하여 스케일아웃 솔루션을 위한 최고의 TCO를 제공하여 고객이 최대 624GB의 빠른 액세스 메모리를 사용하여 더 큰 데이터셋, 더 복잡한 모델 및 새로운 워크로드를 처리할 수 있도록 합니다. 또한 NVIDIA GH200은 두 개의 Grace Hopper Superchip이 NVLink에 완전히 연결된 GH200 NVL2 구성으로 제공되어 컴퓨팅 및 메모리 집약적인 워크로드 모두에 288GB의 HBM3e와 1.2TB의 빠른 메모리를 제공합니다.
-
Hopper H100 GPU의 성능 및 속도
H100 Tensor Core GPU는 NVIDIA의 9세대 데이터 센터 GPU로, 이전 세대의 NVIDIA A100 Tensor Core GPU보다 대규모 AI 및 HPC 성능을 한 단계 더 향상시켰습니다. 새로운 Hopper GPU 아키텍처를 기반으로 한 NVIDIA H100은 여러 혁신을 특징으로 합니다.
-
일관된 메모리의 힘
NVLink-C2C 메모리 일관성은 개발자의 생산성, 성능 및 GPU 접근 가능한 메모리의 양을 증가시킵니다. CPU와 GPU 스레드는 동시에 투명하게 CPU와 GPU 상주 메모리에 접근할 수 있어 개발자는 명시적인 메모리 관리 대신 알고리즘에 집중할 수 있습니다. 메모리 일관성을 통해 개발자는 필요한 데이터만 전송하고 전체 페이지를 GPU로 또는 GPU에서 마이그레이션할 수 없습니다. 또한 CPU와 GPU 모두에서 네이티브 원자를 가능하게 하여 GPU와 CPU 스레드 전반에 걸쳐 가벼운 동기화 기본 요소를 제공합니다. 4세대 NVLink는 직접 로드, 저장소 및 원자 연산을 통해 피어 메모리에 접근할 수 있으므로 가속화된 애플리케이션은 그 어느 때보다 더 큰 문제를 쉽게 해결할 수 있습니다.
-
Grace CPU를 통한 전력 및 효율성
NVIDIA Grace CPU는 기존 x86 플랫폼보다 와트당 2배의 성능을 제공합니다. Grace CPU는 높은 단일 스레드 성능, 높은 메모리 대역폭, 뛰어난 데이터 이동 기능을 위해 설계되었습니다. NVIDIA Grace CPU는 72개의 Neoverse V2 Armv9 코어와 최대 480GB의 서버급 LPDDR5X 메모리를 ECC와 결합합니다. 와이드 메모리 하위 시스템은 비슷한 비용으로 기존 DDR 메모리의 5분의 1 전력으로 최대 500GB/s의 대역폭을 제공합니다.
-
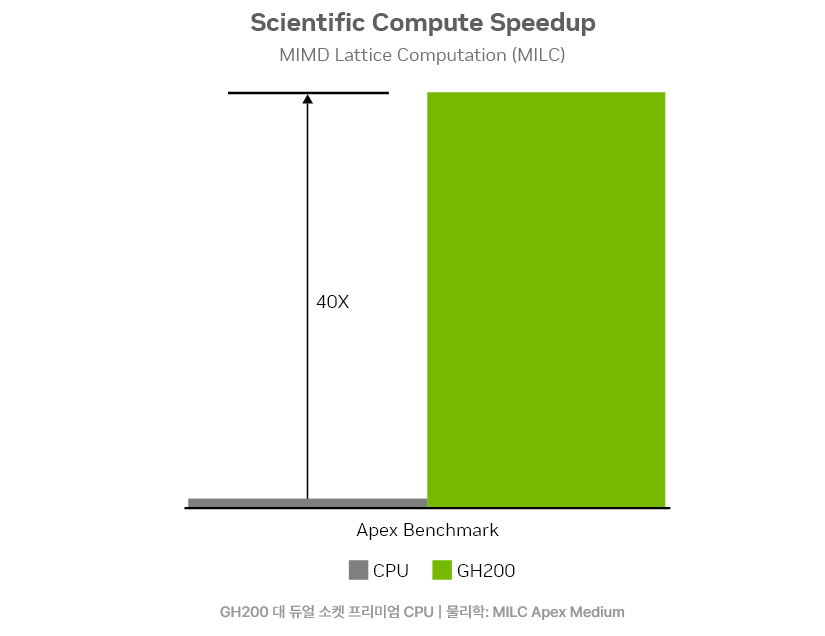
과학적 컴퓨팅
NVLink-C2C를 사용하여 Arm® 기반 Grace CPU와 Hopper GPU 아키텍처를 결합한 NVIDIA GH200 Superchips는 전 세계 슈퍼컴퓨터의 과학 연구 및 발견 속도를 높이고 있습니다. NVIDIA Grace Hopper Superchips를 활용하는 슈퍼컴퓨터는 모두 200엑사플롭스(초당 200경 회 계산)의 에너지 효율적인 AI 처리 능력을 제공합니다.
-

데이터 처리
최근 스토리지 및 네트워킹 대역폭의 발전과 무어의 법칙의 종말로 인해 분석 및 쿼리 병목 현상이 CPU로 옮겨갔습니다. GH200을 사용하면 CPU와 GPU가 프로세스당 단일 페이지 테이블을 공유하여 모든 CPU 및 GPU 스레드가 물리적 CPU 또는 GPU 메모리에 상주할 수 있는 모든 시스템 할당 메모리에 액세스할 수 있습니다. GH200은 CPU와 GPU 간에 메모리를 서로 복사할 필요성을 없애 데이터 처리 속도를 최대 36배까지 향상시킵니다.
-
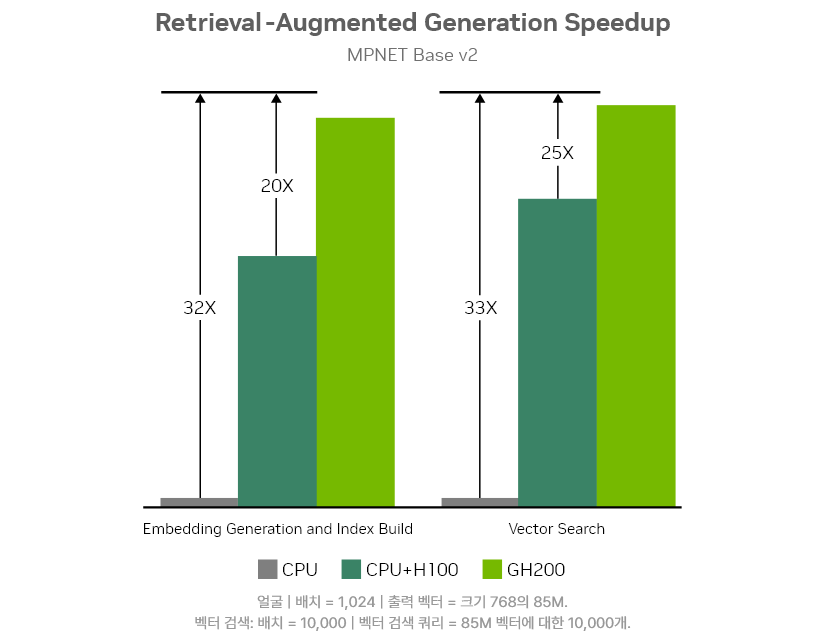
검색 증강 생성
검색 증강 생성(RAG)은 대규모 언어 모델(LLM)을 지식 기반과 연결하여 모델 정확도를 향상시킵니다. RAG를 사용하려면 임베딩을 생성하고 벡터 검색을 대규모로 실행해야 합니다. 72개의 전력 효율적인 Arm 기반 Grace CPU 코어는 지식 기반 데이터의 전처리를 가속화하고, NVLink-C2C는 전처리된 데이터를 Hopper GPU로 전송하는 속도를 PCIe 대비 7배 빠르게 하여 임베딩 생성 프로세스를 30배 가속화합니다.
-
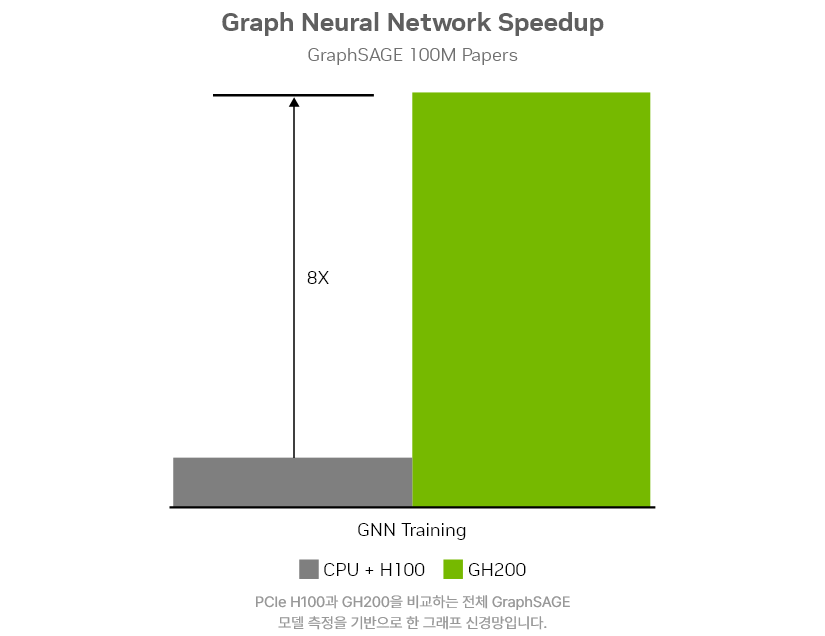
그래프 신경망
그래프 신경망(GNN)은 소셜 네트워크 분석, 신약 개발, 사기 탐지, 분자 화학 등 다양한 분야에 활용됩니다. GH200은 최대 624GB의 CPU 및 GPU 고속 메모리, 4페타플롭스의 H200 GPU, 그리고 900GB/s 속도의 NVLink-C2C를 활용하여 H100 PCIe GPU 대비 최대 8배 빠른 GNN 학습 속도를 제공합니다.
Platform Full stack Provider 리더스시스템즈는
DGX System 기반 AI 데이터센터 통합 솔루션을 제공합니다.
회사소개 바로가기
-

NVIDIA Partner Network 인증 파트너
리더스시스템즈는 NVIDIA Elite Partner로서 Blackwell 및 Grace 기반 시스템 도입 경험을 바탕으로 소프트웨어 스택(NVIDIA AI Enterprise)과 시스템 튜닝을 고객의 워크로드에 맞춰 최적화합니다.
-

AI 인프라 구축·운영 토탈 서비스
설계부터 구축, 운영, 최적화까지 모든 단계를 직접 지원합니다. 고객의 비즈니스 확장 속도에 맞춘 모듈형 확장과 고가용성(HA) 설계로 장기 운영 신뢰성을 보장합니다.
-

운영 효율을 높이는 전문 기술 지원
구축 이후에도 모니터링, 정기 점검, 운영 교육을 지속적으로 지원하며, 이슈 발생 시 신속한 대응으로 다운타임을 최소화하고 데이터센터 TCO 최적화를 실현합니다.
-

글로벌 파트너십 기반 Full-Stack 공급
시스템 도입에 필요한 보안, 전력(UPS), 냉각 시스템, 네트워크 및 스토리지까지 검증된 글로벌 기업들과의 기술 협력을 통해 통합 솔루션을 제공합니다.
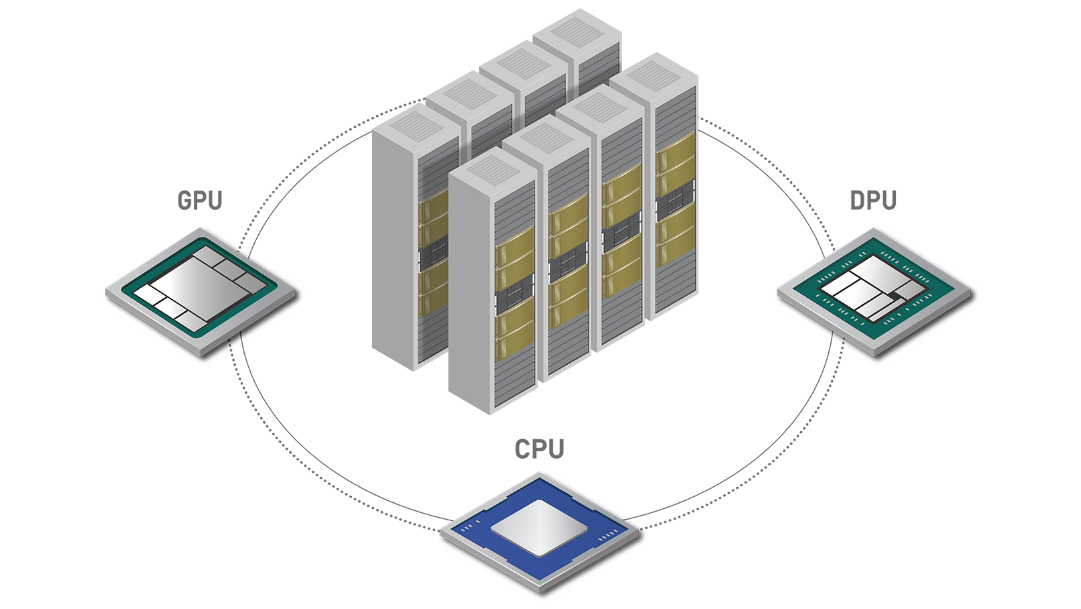
AI와 데이터 분석에서 고성능 컴퓨팅(HPC)과 렌더링까지, NVIDIA 통합 플랫폼
GPU, DPU 및 CPU용 3개의 차세대 아키텍처를 기반으로 구축된 NVIDIA 가속 컴퓨팅 플랫폼으로 AI 시대의 데이터센터를 재구성하세요.
이러한 아키텍처는 성능, 보안, 네트워킹 등을 포괄하는 최첨단 기술을 통해 최신 데이터센터의 모든 문제를 처리할 준비가 되어 있습니다.
AI 학습, 추론, 5G 및 HPC를 위한
GH200을 탑재한 NVIDIA MGX
NVIDIA MGX™는 다양한 엔터프라이즈 워크로드를 가속화할 수 있는 모듈형 레퍼런스 디자인입니다. GH200 Superchip의 고급 기능과 NVIDIA BlueField®-3 DPU, OEM에서 정의한 입출력(IO), 그리고 4세대 NVLink를 통합하여 최신 데이터 센터에 맞는 맞춤형 솔루션을 제공합니다.
자세히 보기
Product Specifications
| Feature | GH200 | GH200 NVL2 |
|---|---|---|
| CPU core count | 72 Arm Neoverse V2 cores | 144 Arm Neoverse V2 cores |
| L1 cache | 64KB i-cache + 64KB d-cache | 64KB i-cache + 64KB d-cache |
| L2 cache | 1MB per core | 1MB per core |
| L3 cache | 114MB | 228MB |
|
Base frequency | all-core single instruction, multiple data (SIMD) frequency |
3.1GHz | 3.0GHz | 3.1GHz | 3.0GHz |
| LPDDR5X size | 480GB, 240GB, 120GB | 960GB, 480GB, 240GB |
| Memory bandwidth | Up to 384GB/s | Up to 512GB/s | Up to 768GB/s | Up to 1024GB/s |
| PCIe links | Up to 4× PCIe x16 (Gen5) | Up to 8× PCIe x16 (Gen5) |
| Feature | GH200 | GH200 NVL2 |
|---|---|---|
| FP64 | 34 teraFLOPS | 68 teraFLOPS |
| FP64 Tensor Core | 67 teraFLOPS | 134 teraFLOPS |
| FP32 | 67 teraFLOPS | 134 teraFLOPS |
| TF32 Tensor Core | 989 teraFLOPS | 494 teraFLOPS | 1,979 teraFLOPS | 990 teraFLOPS |
| BFLOAT16 Tensor Core | 1,979 teraFLOPS | 990 teraFLOPS | 3,958 teraFLOPS | 1,979 teraFLOPS |
| FP16 Tensor Core | 1,979 teraFLOPS | 990 teraFLOPS | 3,958 teraFLOPS | 1,979 teraFLOPS |
| FP8 Tensor Core | 3,958 teraFLOPS | 1,979 teraFLOPS | 7,916 teraFLOPS | 3,958 teraFLOPS |
| INT8 Tensor Core | 3,958 TOPS | 1,979 TOPS | 7,916 TOPS | 3,958 TOPS |
| HBM size | 96GB HBM3 | 144GB HBM3e | Up to 288GB HBM3e |
| Memory bandwidth | Up to 4TB/s | Up to 4.9TB/s | Up to 9.8TB/s |
| NVIDIA NVLink-C2C CPU-to-GPU bandwidth |
900GB/s | 1800GB/s |
| Power | Configurable 450 to 1000W (Memory + CPU + GPU) |
Configurable 900W to 2000W (Memory + CPU + GPU) |
| Thermal solution | Air-cooled or liquid-cooled | Air-cooled or liquid-cooled |
- * With sparsity
클라우드 및 데이터센터를 위한 리소스
-
 자세히 보기
자세히 보기Enterprise AI를 위한 소프트웨어
NVIDIA AI Enterprise는 신뢰할 수 있고 안전하며 확장 가능한 AI 운영을 보장하는 동시에 출시 시간을 가속화하고 인프라 비용을 절감할 수 있습니다.
-
 자세히 보기
자세히 보기슈퍼컴퓨팅 인프라를 위한 네트워킹
NVIDIA® BlueField® 네트워킹 플랫폼은 클라우드에서 데이터센터, 엣지에 이르기까지 모든 환경에서 모든 워크로드에 안전하고 가속화된 인프라를 제공합니다.
-
 자세히 보기
자세히 보기전문가와 상담하기
리더스시스템즈는 기술 전문가들, 다양한 글로벌 기업과 지속적인 파트너쉽을 체결하여 고객에게 가장 효율적인 고성능 네트워크를 구축할 수 있도록 합니다.