
제품문의
제품과 관련하여 궁금하신 사항을
문의하기를 통해 해결하세요.

최근 떠오르고 있는 1조 매개 변수 모델을 비롯한 AI 및 HPC에서 컴퓨팅 수요가 증가함에 따라 모든 GPU 간의 원활한 고속 통신이 가능한 멀티 노드, 멀티 GPU 시스템의 필요성이 높아지고 있습니다. 비즈니스 속도를 충족할 수 있는 가장 강력한 엔드 투 엔드 컴퓨팅 플랫폼을 구축하려면 빠르고 확장 가능한 상호 연결이 필요합니다.
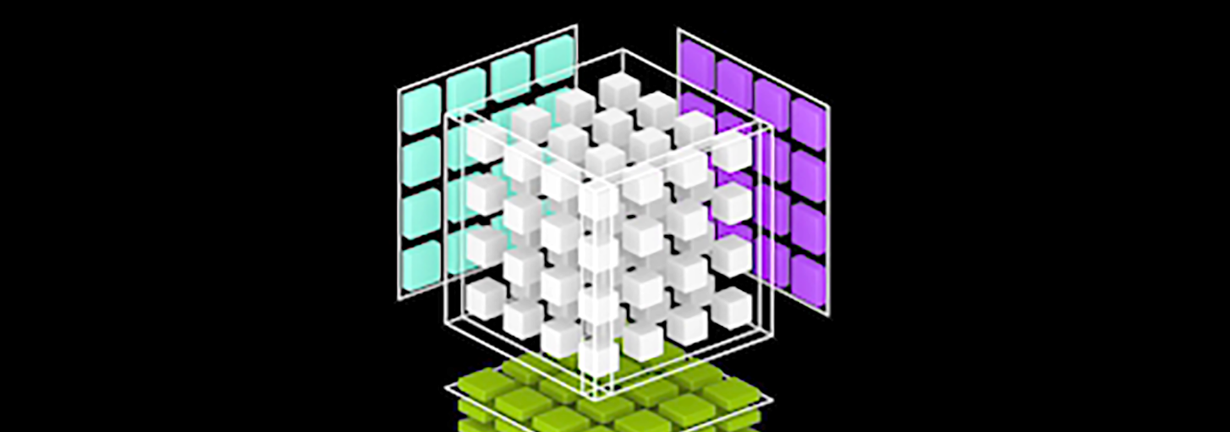
NVLink™는 다중 GPU 시스템에 사용되는 기존의 PCE-E 기반 솔루션보다 훨씬 빠른 대안을 제공하는 세계 최초의 고속 GPU 상호 연결입니다. NVLink를 통해 두 개의 NVIDIA 그래픽 카드를 연결하면 메모리와 성능을 확장1하면 가장 큰 전문적인 비주얼 컴퓨팅 워크로드의 요구사항도 만족시킬 수 있습니다.

NVLink는 전문 애플리케이션의 멀티 GPU 구성을 통해 메모리와 성능을 쉽게 확장할 수 있게 합니다. 다양한 시스템에 맞는 로우 프로파일 디자인을 갖춘 NVIDIA NVLink 브리지를 통해 2개의 NVIDIA TITAN GPU를 연결할 수 있습니다.
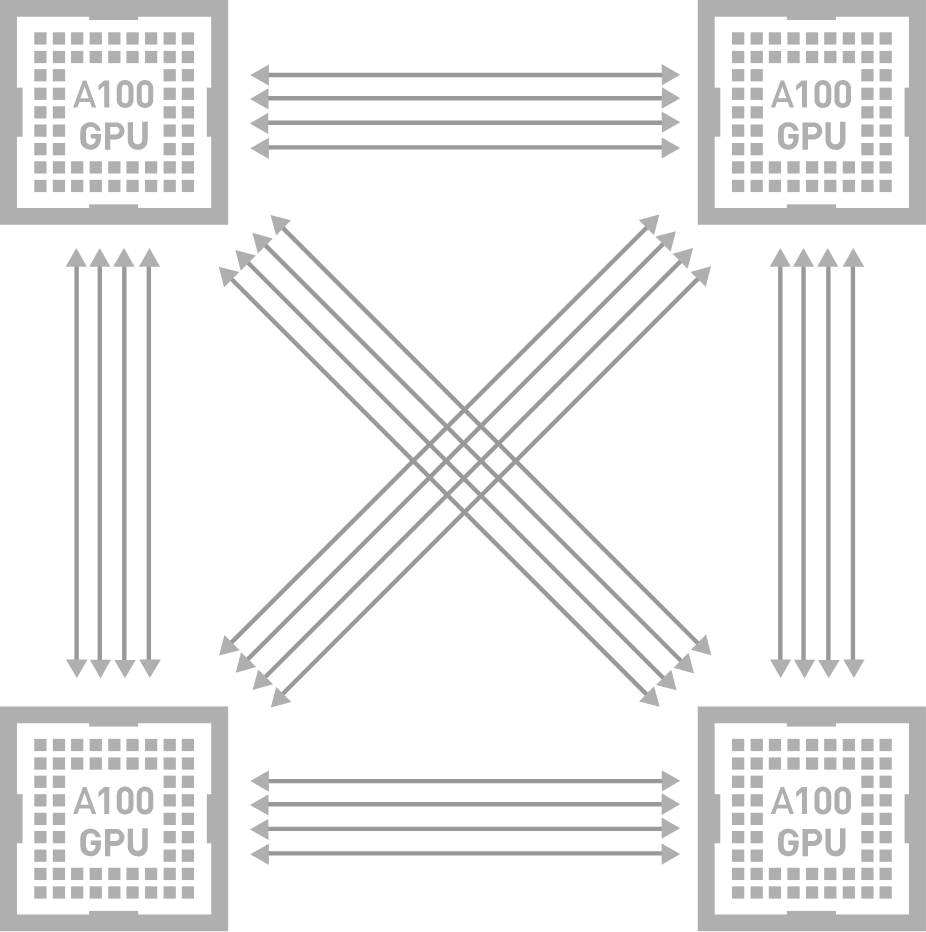
NVIDIA® NVLink®는 GPU 간 고속 직접 상호 연결입니다. NVIDIA NVSwitch™는 여러 NVLink를 통합함으로써 NVIDIA HGX™ A100과 같은 단일 노드 내에서 올 투 올 GPU 통신을 최대 NVLink 속도로 제공하여 한 차원 높은 상호 연결성을 제공합니다. NVIDIA는 NVLink와 NVSwitch를 조합하여 AI 성능을 효율적으로 여러 GPU로 확장하고 최초의 범산업 AI 벤치마크인 MLPerf 0.6을 획득할 수 있었습니다.

GPU 간 연결을 위한 NVLink가 지원되는 NVIDIA A100 PCle
NVLink GPU 간 연결을 지원하는 NVIDIA A100
NVSwitch 토폴로지 다이어그램은 간단하게 이해할 수 있도록 두 GPU 간의 연결을 보여줍니다.
8장 또는 16장의 GPU는 모두 같은 방식으로 NVSwitch를 통해 올 투 올 연결됩니다.

NVIDIA A100의 NVLink는 기존 세대 대비 GPU 간의 통신 대역폭을 두 배로 확장하므로 연구원들은 복잡한 문제의 해결을 위해 더 크고 정교한 애플리케이션을 사용할 수 있습니다.
NVIDIA® NVLink®는 GPU 간 고속 직접 상호 연결입니다. NVIDIA NVSwitch™는 여러 NVLink를 통합함으로써 NVIDIA HGX™ A100과 같은 단일 노드 내에서 올 투 올 GPU 통신을 최대 NVLink 속도로 제공하여 한 차원 높은 상호 연결성을 제공합니다. NVIDIA는 NVLink와 NVSwitch를 조합하여 AI 성능을 효율적으로 여러 GPU로 확장하고 최초의 범산업 AI 벤치마크인 MLPerf 0.6을 획득할 수 있었습니다.
NVLink는 전문 애플리케이션의 멀티 GPU 구성을 통해 메모리와 성능을 쉽게 확장할 수 있게 합니다. 다양한 시스템에 맞는 로우 프로파일 디자인을 갖춘 NVIDIA NVLink 브리지를 통해 2개의 RTX GPU을 연결할 수 있습니다. 이로써 최대 112GB/s의 대역폭 및 결합된 GDDR6 메모리를 제공하여 가장 메모리 집약적인 워크로드를 처리합니다.
NVIDIA의 NVLink 및 NVSwitch는 완전한 NVIDIA 데이터센터 솔루션의 구성 요소입니다. 이 솔루션은 하드웨어, 네트워킹, 소프트웨어, 라이브러리, 그리고 NGC™의 최적화된 AI 모델 및 애플리케이션을 통합합니다. 연구원은 가장 강력한 엔드 투 엔드 AI 및 HPC 플랫폼을 통해 실제 결과를 제공하고 솔루션을 프로덕션에 배포하여 모든 규모의 전례 없는 가속화를 제공할 수 있습니다.
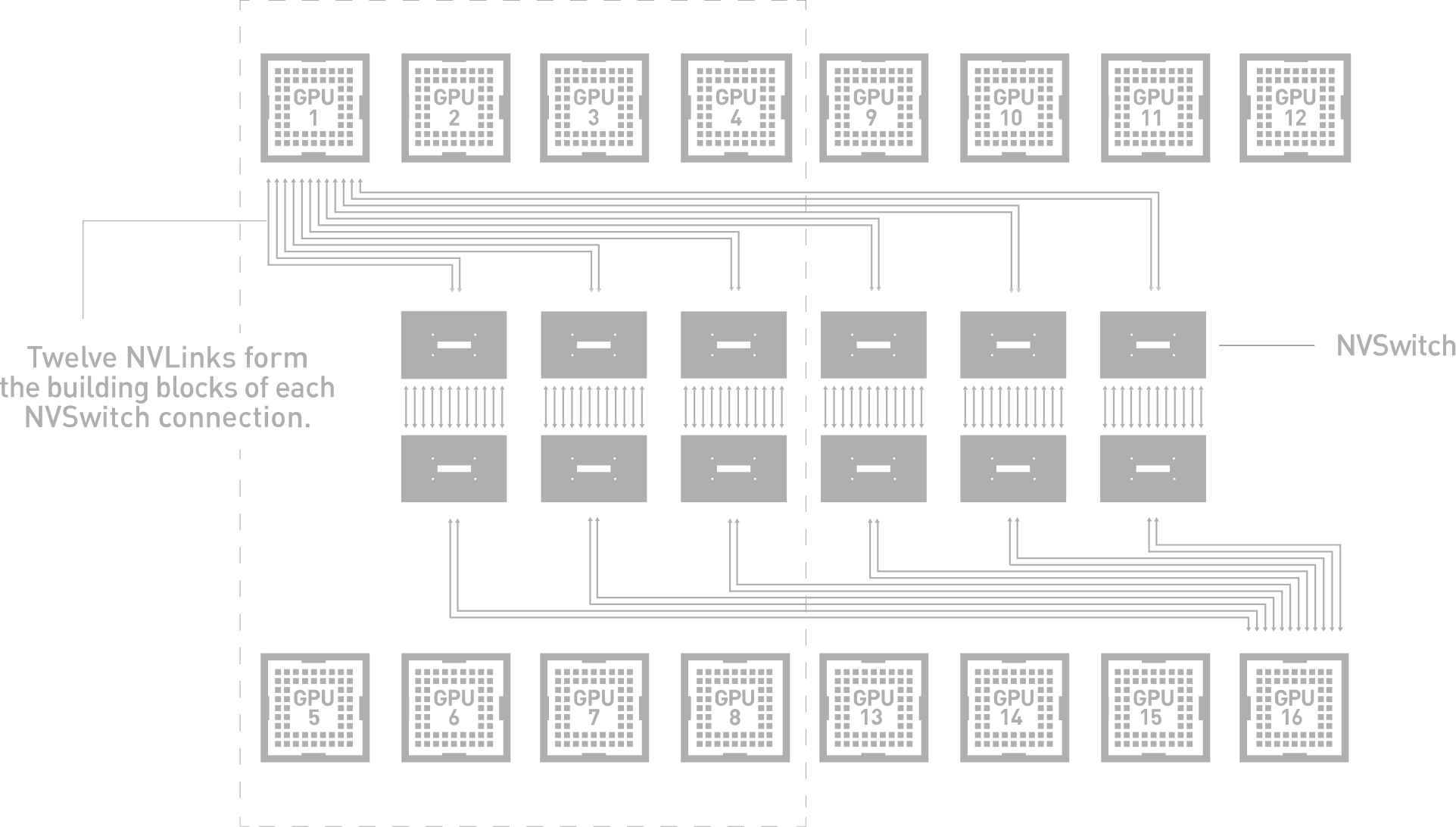
NVSwitch는 단일 서버 노드에서 완전히 연결된 8-16개의 GPU를 지원하는 최초의 노드 간 스위치 아키텍처로 2세대의 경우 600GB/s 속도로 모든 GPU 사이에 동시 통신을 지원합니다. 직접적인 GPU Peer-to-per 메모리 주소 지정으로 완전한 올 투 올 통신을 지원하며 16장의 GPU는 통합 메모리 공간과 최대 10PetaFlop의 딥 러닝 컴퓨팅 가능한 단일 고성능 가속기로 사용 가능합니다.
멀티 GPU 시스템 수준에서 PCIe 대역폭이 병목 현상을 일으키는 경우가 잦아 딥 러닝의 신속한 도입은 속도와 확장성이 향상된 상호 연결 기술에 대한 수요를 증가시켰습니다. 딥 러닝 워크로드의 확장을 위해서는 대폭 증가된 대역폭과 감소된 지연 시간이 요구됩니다. NVIDIA NVSwitch는 이 문제를 해결하기 위해 NVLink의 고급 통신 기능을 기반으로 구축됩니다. 단일 서버에서 더 많은 GPU를 지원하며 이러한 GPU 사이에 완전한 대역폭 연결성을 보장하는 GPU 패브릭으로 딥 러닝 성능을 다음 단계로 끌어올립니다. 각 GPU의 NVLink 12개가 NVSwitch로 완전히 연결되어 올투올(All-to-all) 고속 통신을 지원합니다.


| 상품명 | NVIDIA TITAN RTX NVLink HB Bridge 4-Slot |
|---|---|
| 출시년월 | 2018년 12월 |
| 제조사 | NVIDIA Corporation |
| 제조국 | China |
| 정품 품질 보증 | 3년 무상보증 |