제품문의
제품과 관련하여 궁금하신 사항을
문의하기를 통해 해결하세요.
72 NVIDIA Blackwell Ultra GPUs, 36 NVIDIA Grace CPUs
FP4 Tensor Core 1,400 | 1,100 PFLOPS
FP8/FP6 Tensor Core 720 PFLOPS
INT8 Tensor Core 23 POPS
FP16/BF16 Tensor Core 360 PFLOPS
TF32 Tensor Core 180 PFLOPS
FP32 6 PTFLOPS

딥 러닝 워크스테이션 솔루션을 통해 작업 공간에서 편리하게 AI 슈퍼 컴퓨팅 성능을 활용하고 NGC에서 필요한 모든 딥 러닝 소프트웨어를 사용할 수 있습니다. 이제 딥 러닝을 필요로 하는 누구든지 데스크 사이드 딥 러닝을 시작할 수 있습니다.
모든 엔터프라이즈에서 물리적 데이터센터를 구축할 필요 없이 손쉽게 대규모 컴퓨팅 성능에 액세스할 수 있습니다. AI, 고성능 컴퓨팅(HPC) 및 의료 영상 활용, 차세대 그래픽 기술 적용 등 워크로드 전반에서 최고 성능을 경험할 수 있습니다.
GPU 가속 데이터센터는 원하는 규모와 더 적은 수의 서버로 컴퓨팅 및 그래픽 워크로드에 혁신적인 성능을 제공하여 더 빠르게 정보를 얻고 비용을 획기적으로 절감할 수 있습니다. 가장 복잡한 딥 러닝 모델을 트레이닝하여 가장 심각한 문제를 해결하세요.
현대 기업은 이제 수 십억 개의 IoT 센서를 통해 생성 된 데이터를 활용해 더 빠른 통찰력과 시간과 비용 절감을 할 수 있습니다. 실시간으로 결정을 내리고 강력하고 분산 된 컴퓨팅과 안전하고 간단한 원격 관리 및 업계 최고 기술과의 호환성을 기대할 수 있습니다.
NVIDIA GB300 NVL72는 완전 액체 냉각 방식의 랙 규모 설계를 갖추고 있으며, 72개의 NVIDIA Blackwell Ultra GPU와 36개의 Arm® 기반 NVIDIA Grace™ CPU를 단일 플랫폼에 통합해 테스트 시 확장형 추론에 최적화되어 있습니다. 이는 NVIDIA Hopper™ 플랫폼보다 65배 더 많은 AI 컴퓨팅, 40테라바이트(TB)의 고속 메모리, Quantum-X800 InfiniBand 또는 Spectrum™-X 이더넷을 사용하는 NVIDIA® ConnectX®-8 SuperNIC 를 통한 통합 네트워킹을 제공합니다. Blackwell Ultra는 에이전트 시스템과 AI 추론부터 전 세계 AI 팩토리를 위한 실시간 영상 생성까지, 가장 복잡한 워크로드에서도 획기적인 성능을 제공합니다.

NVIDIA 블랙웰 아키텍처는 2,080억 개의 트랜지스터를 갖춘 AI 슈퍼칩으로, 2세대 생성형 AI 엔진을 통해 FP4 AI를 포함한 거대 언어 모델 학습 및 추론을 혁신적으로 가속합니다. 강력한 하드웨어 기반 컨피덴셜 컴퓨팅으로 AI 모델과 데이터를 안전하게 보호하며, 5세대 NVLink 및 NVLink Switch로 초고속 통신을 지원하여 엑사스케일 AI를 구현합니다.

모델의 복잡성이 폭발적으로 증가함에 따라 AI의 요구 사항을 충족하기 위해 가속 컴퓨팅과 에너지 효율성이 매우 중요해지고 있습니다. NVIDIA Grace™ CPU는 독보적인 성능과 효율성을 제공하는 획기적인 Arm® CPU입니다. GPU와 긴밀하게 결합되어 가속 컴퓨팅을 강화하거나 강력하고 효율적인 독립형 CPU로 배포할 수 있습니다.
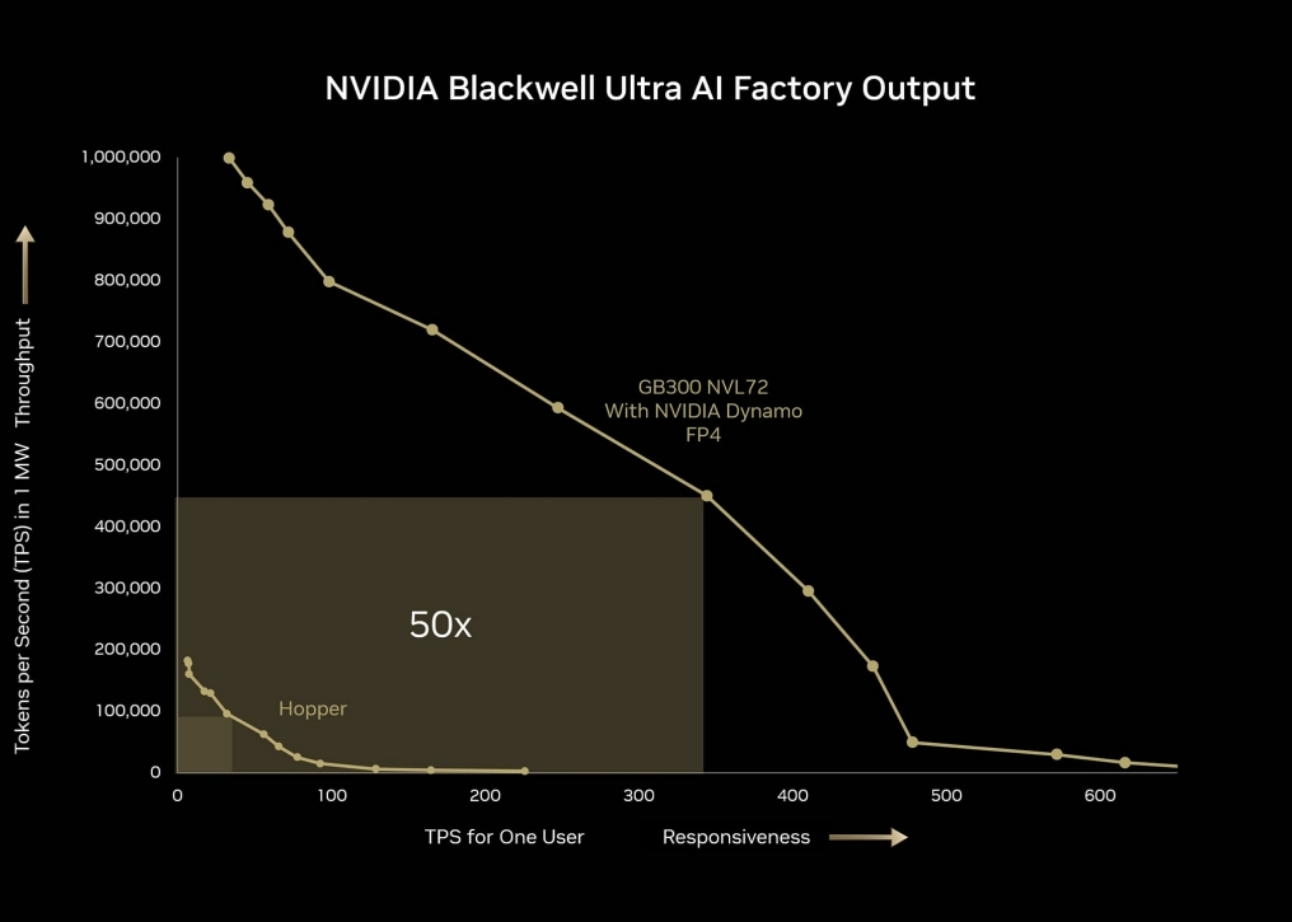
NVIDIA GB300 NVL72 플랫폼으로 차원이 다른 AI 추론 성능을 경험해 보세요. GB300 NVL72는 Hopper에 비해 사용자 응답성(사용자당 TPS)이 10배 향상되고 처리량(메가와트(MW)당 TPS)이 5배 향상되었습니다. 이러한 발전이 결합되어 AI 팩토리의 전체 출력이 무려 50배 향상되는 놀라운 성능 향상을 이뤄냅니다.
DeepSeek R1 ISL = 32K, OSL = 8K, GB300 NVL72(FP4 Dynamo 세분화 포함). H100(FP8 인플라이트 배칭 포함). 예상 성능은 변경될 수 있습니다.

테스트 시간 확장 및 AI 추론은 서비스 품질과 처리량을 극대화하는 데 필요한 컴퓨팅을 증가시킵니다. NVIDIA Blackwell Ultra의 Tensor 코어는 Blackwell GPU 대비 2배 향상된 어텐션 레이어 가속화와 1.5배 더 많은 초당 AI 컴퓨팅 부동 소수점 연산(FLOPS)을 갖추고 있습니다.

메모리 용량이 클수록 배치 크기 조정과 처리량 성능을 극대화할 수 있습니다. NVIDIA Blackwell Ultra GPU는 1.5배 더 큰 HBM3e 메모리와 추가된 AI 컴퓨팅을 함께 제공하여 가장 긴 컨텍스트 길이에 대한 AI 추론 처리량을 향상합니다.

NVIDIA Blackwell 아키텍처는 가속 컴퓨팅 분야에서 획기적인 발전을 제공하여 탁월한 성능, 효율성, 확장성을 갖춘 새로운 시대를 열어가고 있습니다.

NVIDIA ConnectX-8 SuperNIC의 입출력(IO) 모듈은 2개의 ConnectX-8 장치를 호스팅하여, NVIDIA GB300 NVL72의 각 GPU에 초당 800기가비트(Gb/s)의 네트워크 연결을 제공합니다.

NVIDIA Grace CPU는 최신 데이터센터 워크로드를 위해 설계된 획기적인 프로세서입니다. 오늘날의 주요 서버 프로세서에 비해 2배 높은 에너지 효율로 탁월한 성능과 메모리 대역폭을 제공합니다.

가속 컴퓨팅의 잠재력을 최대한 활용하려면 모든 GPU 간에 원활한 통신이 이루어져야 합니다. 5세대 NVIDIA NVLink™는 AI 추론 모델의 성능을 극대화하는 스케일업 인터커넥트 기술입니다.
가속화된 인프라, 엔터프라이즈급 소프트웨어 및 AI 모델 전반에 걸친 풀스택 혁신을 통해 모든 기업을 AI 조직으로 전환하세요. 전체 AI 워크플로우를 가속화함으로써 다양한 솔루션과 애플리케이션의 전반적인 비용을 절감하면서 프로젝트가 더 빠르게 운영 단계에 진입하고, 더 높은 정확도, 효율성 및 인프라 성능을 확보할 수 있습니다.
딥 러닝 신경망이 더욱 복잡 해짐에 따라 훈련 시간이 크게 증가하여 생산성이 낮아지고 비용이 높아집니다. NVIDIA의 딥 러닝 기술과 완전한 솔루션 스택은 AI 교육을 크게 가속화하여 더 짧은 시간에 더 깊은 통찰력을 얻고 상당한 비용을 절감하며 ROI 달성 시간을 단축합니다. 최신 추론 및 생성 AI 모델 에 최적화된 추론 성능을 확보하세요. NIM에는 NVIDIA® TensorRT™ , TensorRT-LLM 등 NVIDIA 및 커뮤니티에서 제공하는 가속 추론 엔진이 함께 제공되며, NVIDIA 가속 인프라에서 저지연, 고처리량 추론을 위해 사전 구축 및 최적화되었습니다.
NVIDIA AI 데이터 플랫폼은 엔터프라이즈 스토리지 선도업체들이 에이전트 AI 워크플로의 성능과 정확성을 향상시키기 위해 구축했습니다. 이 플랫폼은 NVIDIA Blackwell GPU, BlueField®-3 DPU, Spectrum™-X 네트워킹, 그리고 NVIDIA AI Enterprise 소프트웨어를 갖추고 있습니다.

데이터 과학 워크플로는 전통적으로 느리고 복잡했으며, 데이터 로드, 필터링, 조작, 모델 학습 및 배포에 CPU에 의존했습니다. RAPIDS™ 오픈소스 소프트웨어 라이브러리를 포함한 NVIDIA AI 소프트웨어를 사용하면 GPU를 통해 인프라 비용을 크게 절감하고 엔드투엔드 데이터 과학 워크플로에 탁월한 성능을 제공할 수 있습니다. GPU 가속 데이터 과학은 노트북, 데이터 센터, 엣지, 클라우드 등 어디에서나 활용 가능합니다.
AI 추론은 사전 학습된 AI 모델을 배포하여 새로운 데이터를 생성하는 과정이며, AI가 결과를 도출하고 모든 산업 분야에서 혁신을 촉진하는 곳입니다. AI 모델은 규모, 복잡성, 그리고 다양성 측면에서 빠르게 확장되고 있으며, 가능성의 경계를 넓히고 있습니다. AI 추론을 성공적으로 활용하려면 조직은 엔드 투 엔드 AI 수명 주기를 지원하는 풀스택 접근 방식과 새로운 확장 법칙 시대에 팀이 목표를 달성할 수 있도록 지원하는 도구가 필요합니다.
대화형 AI 는 AI 가상 비서, 디지털 휴먼, 챗봇 등 자동화된 메시징 및 음성 지원 애플리케이션을 구동하는 기술로, 개인화되고 자연스러운 인간-기계 대화를 위한 혁신적인 길을 열어가고 있습니다. 하지만 이러한 기술은 유용성을 위해 정확성과 속도가 필수적입니다. 생성 , 음성 및 번역을 위한 NVIDIA NIM™ 마이크로서비스를 포함한 NVIDIA의 대화형 AI 솔루션을 통해 개발자는 실시간 상호작용에 필요한 높은 정확도와 빠른 응답을 제공하는 최첨단 모델을 신속하게 구축하고 배포할 수 있습니다.

사이버 위협은 그 수와 정교함이 날로 증가하고 있습니다. NVIDIA는 기업이 AI와 가속 컴퓨팅을 통해 더욱 강력한 사이버 보안 솔루션을 제공하고, AI를 통해 위협 탐지를 강화하며, 생성적 AI를 통해 보안 운영 효율성을 높이고, 안전한 인프라를 통해 민감한 데이터와 지적 재산을 보호할 수 있도록 지원하는 독보적인 입지를 갖추고 있습니다. NVIDIA는 강력한 AI 프레임워크, 아키텍처, 그리고 모범 사례를 결합하여 제로 트러스트 및 확장 가능한 AI 데이터 센터를 구축하고, 고조되는 보안 위협에 맞서 사이버 보안을 강화합니다.
생성형 AI는 텍스트, 이미지, 3D 모델 등 다양한 입력 데이터를 활용하여 콘텐츠, 솔루션, 그리고 인사이트를 생성하는 능력을 통해 산업에 혁신을 일으키고 있습니다. 이러한 다재다능함은 기업이 기본적인 자동화를 넘어 AI 에이전트를 활용하여 여러 단계의 문제를 해결하고 생산성을 향상시킬 수 있도록 지원합니다. 초기 생성형 AI 애플리케이션인 챗봇은 자연어 질의 및 응답과 같은 단일 상호작용 솔루션을 제공했습니다. 그러나 미래는 고급 추론과 반복적 계획을 활용하여 복잡한 문제를 해결하는 자율 시스템 인 에이전트적 AI 에 달려 있습니다.
데이터 사이언스와 AI를 발전시키려면 조직은 클라우드 및 데이터센터에서 엣지에 이르는 GPU 기반 시스템을 최적화할 수 있는 도구를 이용해야 합니다.
NVIDIA의 소프트웨어 솔루션은 모든 최신 워크로드를 포괄하므로 IT 관리자, 데이터 사이언티스트, DevOps 팀과 개발자가 필요한 것을 빠르고 쉽게 이용할 수 있습니다.

모든 조직에서 AI를 사용할 수 있도록 최적화된 엔드 투 엔드 클라우드 기반 AI 및 데이터 분석 소프트웨어 제품군입니다. 엔터프라이즈 데이터센터에서 퍼블릭 클라우드에 이르기까지 어디에서나 배포할 수 있도록 인증받았고, AI 프로젝트를 순조롭게 진행하기 위한 글로벌 엔터프라이즈 지원이 포함됩니다.
CUDA-X AI는 딥 러닝, 머신 러닝 및 HPC(고성능 컴퓨팅)를 위한 필수 최적화를 제공하는 NVIDIA의 획기적인 병렬 프로그래밍 모델인 CUDA® 위에 구축된 소프트웨어 가속화 라이브러리 컬렉션입니다. cuDNN, cuML, NVIDIA® TensorRT™, cuDF, cuGraph 및 13개 이상의 기타 라이브러리가 포함됩니다.
NVIDIA Magnum IO™는 병렬의 비동기식 지능형 데이터센터 IO를 위한 아키텍처로, 멀티 GPU, 멀티 노드 가속화를 위해 스토리지 및 네트워크 IO 성능을 극대화합니다. 스토리지 IO, 네트워크 IO, 인-네트워크 컴퓨팅 및 IO 관리를 활용하여 멀티 GPU, 멀티 노드 시스템을 위한 데이터 이동, 액세스 및 관리를 단순화하고 가속화합니다.
NVIDIA Fleet Command™를 통해 엣지에서 시스템과 AI 애플리케이션의 프로비저닝 및 배포를 간소화하세요. 컨테이너 오케스트레이션을 위한 관리형 플랫폼으로, 클라우드의 확장성과 복원력을 갖춘 분산 컴퓨팅 환경의 관리를 단순화하여 모든 사이트를 안전한 지능형 위치로 전환합니다.
NVIDIA® Riva는 완전히 사용자 정의 가능한 실시간 대화형 AI 파이프라인을 구축하기 위한 GPU 가속 다국어 음성 및 번역 마이크로서비스 세트입니다. Riva에는 자동 음성 인식(ASR), 텍스트 음성 변환(TTS), 신경 기계 번역(NMT)이 포함되며 모든 장치에 배포할 수 있습니다. LLM(대형 언어 모델) 및 RAG(검색 증강 생성)를 활용하세요.
엣지, 데이터 센터, 멀티 및 하이브리드 클라우드 환경에서 이기종 AI 및 고성능 컴퓨팅(HPC) 클러스터에 대한 빠른 배포와 엔드투엔드 관리를 제공합니다. 몇 개의 노드에서 수십만 개의 노드에 이르는 클러스터의 프로비저닝 및 관리를 자동화하고, NVIDIA GPU 가속 및 기타 시스템을 지원하며, Kubernetes와의 오케스트레이션을 활성화합니다.
NVIDIA NGC™는 엔터프라이즈 서비스, 소프트웨어, 관리 도구, 엔드 투 엔드 AI 및 디지털 트윈 워크플로우 지원을 위한 포털입니다. 완전 관리형 서비스를 통해 솔루션을 더 빠르게 출시하거나, 성능 최적화된 소프트웨어를 활용하여 선호하는 클라우드, 온프레미스, 엣지 시스템에서 솔루션을 구축하고 배포할 수 있습니다.
NVIDIA NeMo™ Agent 툴킷은 프로덕션 AI 에이전트 시스템을 위한 프레임워크 독립적인 프로파일링 및 최적화를 제공하는 오픈소스 라이브러리입니다. 숨겨진 병목 현상과 비용을 노출함으로써 기업이 안정성을 유지하면서 에이전트 시스템을 효율적으로 확장할 수 있도록 지원합니다. (이전, NVIDIA Agent Intelligence 툴킷(AIQ))
NVIDIA Dynamo 플랫폼은 모든 프레임워크, 아키텍처 또는 배포 규모에 걸쳐 모든 AI 모델을 지원하도록 설계된 고성능, 저지연 추론 플랫폼입니다. 단일 엔트리 레벨 GPU에서 이미지 인식을 실행하든 수십만 개의 데이터센터 GPU에 걸쳐 수십억 개의 매개변수를 가진 대규모 언어 추론 모델을 배포하든, NVIDIA Dynamo 플랫폼은 확장 가능하고 효율적인 AI 추론을 제공합니다.

칩 파운드리는 최첨단 트랜지스터 기술, 제조 공정, 대규모 칩 팹, 전문 지식, 그리고 풍부한 서드파티 도구 및 라이브러리 제공업체 생태계를 제공합니다. 마찬가지로 NVIDIA AI Foundry에는 Nemotron 및 Edify와 같은 NVIDIA에서 개발한 AI 모델, 인기 있는 오픈 파운데이션 모델, 모델 맞춤화를 위한 NVIDIA NeMo™ 소프트웨어, 그리고 NVIDIA AI 전문가들이 구축하고 지원하는 NVIDIA DGX™ 클라우드의 전용 용량이 포함됩니다. 그 결과, 맞춤형 모델, 최적화된 엔진, 그리고 표준 API를 포함하는 추론 마이크로서비스인 NVIDIA NIM™ 이 생성되며, 어디에나 배포할 수 있습니다.
NVIDIA NeMo™는 거대 언어 모델(LLM), 비전 언어 모델(VLM), 비디오 모델 및 음성 AI를 비롯한 맞춤형 생성형 AI를 어디에서나 개발할 수 있도록 지원하는 엔드투엔드 플랫폼입니다. NVIDIA AI Foundry의 일부인 NeMo를 사용하여 정확한 데이터 큐레이션, 최첨단 맞춤화, 검색 증강 생성(RAG) 및 가속화된 성능을 통해 엔터프라이즈에 적합한 모델을 제공하세요. NeMo는 엔터프라이즈 데이터 및 도메인별 지식을 갖춘 맞춤형 생성형 AI 구축을 위한 플랫폼 및 서비스입니다.
의사 결정 최적화를 위한 오픈 소스 GPU 가속 솔버로, 혼합 정수 선형 계획법 (MILP), 선형 계획법 (LP) 및 차량 경로 문제 (VRP)에 탁월한 성능을 발휘합니다. 수백만 개의 변수와 제약 조건을 가진 대규모 문제를 해결하도록 설계된 cuOpt는 거의 실시간 최적화를 지원하여 상당한 비용 절감 효과를 제공합니다. 혼합 정수 프로그래밍 라이브러리( MIPLIB )에 대한 기록과 라우팅 벤치마크에서 23개의 세계 기록을 보유한 cuOpt는 복잡한 실제 최적화 문제를 해결하는 데 획기적인 성능을 제공합니다.

NVIDIA Mission Control은 세계적 수준의 전문 지식을 소프트웨어로 제공하여 워크로드부터 인프라까지 AI 팩토리 운영을 간소화합니다. NVIDIA Grace Blackwell 데이터센터를 구동하여 추론 및 학습에 즉각적인 민첩성을 제공하는 동시에 인프라 복원력을 위한 풀스택 인텔리전스를 제공합니다. 모든 기업은 하이퍼스케일 효율성으로 AI를 실행하여 AI 실험을 간소화하고 가속화할 수 있습니다.
| GB300 NVL72 | GB300 Grace Blackwell Superchip | |
|---|---|---|
| Configuration | 36 Grace CPU : 72 Blackwell GPUs | 1 Grace CPU : 2 Blackwell GPUs |
| FP4 Tensor Core2 | 1,440 PFLOPS | 40 PFLOPS |
| FP8/FP6 Tensor Core2 | 720 PFLOPS | 20 PFLOPS |
| INT8 Tensor Core2 | 720 POPS | 20 POPS |
| FP16/BF16 Tensor Core2 | 360 PFLOPS | 10 PFLOPS |
| FP32 | 6,480 TFLOPS | 180 TFLOPS |
| FP64 | 3,240 TFLOPS | 90 TFLOPS |
| FP64 Tensor Core | 3,240 TFLOPS | 90 TFLOPS |
| GPU Memory | Bandwidth | Up to 13.5 TB HBM3e | 576 TB/s | Up to 384 GB HBM3e | 16 TB/s |
| NVLink Bandwidth | 130 TB/s | 3.6 TB/s |
| CPU Core Count | 2,592 Arm® Neoverse V2 cores | 72 Arm® Neoverse V2 cores |
| CPU Memory | Bandwidth | Up to 17 TB LPDDR5X | Up to 18.4 TB/s | Up to 480 GB LPDDR5X | Up to 512 GB/s |
| 상품명 | NVIDIA GB300 NVL72 엔비디아코리아 정품 |
|---|---|
| KC 인증번호 | - |
| 정격전압 / 최대소비전력 | - |
| 정품 품질 보증 | 3년 무상보증 |
| 출시년월 | 2024 |
| 제조사 | NVIDIA Corporation |
| 제조국 | - |
| 크기 | - |